
Unconventional Monetary Policy According to HANK
Eric Sims
Notre Dame and NBER
Jing Cynthia Wu
Notre Dame and NBER
Ji Zhang
Tsinghua PBCSF
Current draft: August 20, 2022
Abstract
This paper studies the implications of household heterogeneity for the effective-
ness of quantitative easing (QE). We consider a heterogeneous agent New Keynesian
(HANK) model with uninsurable household income risk. Financial intermediaries are
subject to an endogenous leverage constraint that allows QE to matter. We find that
macro aggregates react very similarly to a QE shock in the HANK model compared
to a representative agent (RANK) version of the model. This finding is robust across
different micro- and macro- distributions of wealth.
We are grateful to Drew Creal, Soroush Ghazi, Jasmine Xiao, as well as seminar and conference
participants at NBER Summer Institute Monetary Economics Meeting, Penn State University, Tsinghua
University, the University of Alabama, 2022 Renmin University of China School of Finance Workshop,
and Marquette University for helpful comments. Sims and Wu acknowledge support from the National
Science Foundation under Grant No. SES-1949107. Ji acknowledges support from the National Natu-
ral Science Foundation of China (No.72003102). Correspondence: [email protected], [email protected],

1 Introduction
In response to the Great Recession, the Federal Reserve (Fed) lowered its short-term pol-
icy rate to zero. With its conventional stabilization tool unavailable, the Fed resorted to
unconventional policy to provide support to the US economy. The most prominent of its
unconventional policy tools was quantitative easing (QE, also referred to as large scale as-
set purchases, or LSAPs). Purchasing longer-term Treasuries and agency mortgage-backed
securities (MBSs), the Fed more than doubled its balance sheet within the span of a few
months in late 2008. By the time it halted active asset purchases in the middle part of the
2010s, the Fed’s balance sheet had quintupled in size relative to its pre-Great Recession level.
The Fed resumed active asset purchases in 2020 in response to the COVID-19 pandemic,
doubling the size of its balance sheet in less than two years.
There is a large and still growing literature on the effectiveness of QE. Most theoretical
work in this literature is based on representative agent New Keynesian (RANK) models –
see, for example, Gertler and Karadi (2013), Sims and Wu (2020, 2021a), and Sims, Wu
and Zhang (forthcoming). At the same time, there has been significant interest in the
implications of micro-level heterogeneity for macroeconomic fluctuations in general, and in
particular with respect to the transmission of monetary policy; i.e., the heterogeneous agent
New Keynesian (HANK) literature (e.g. Kaplan, Moll and Violante 2018, McKay et al.
2016, Auclert 2019, Acharya and Dogra 2020, Alves, Kaplan, Moll and Violante 2020, Ravn
and Sterk 2020, and others). To date, however, this literature has mainly considered the
implications of heterogeneity for conventional monetary policy in the form of movements in
short-term interest rates. The goal of our paper is to marry these two literatures to investigate
whether, and to what extent, household heterogeneity matters for the effectiveness of QE.
1
1
The one exception of which we are aware is Cui and Sterk (2021). However, the underlying frictions for
QE to matter differ in the two papers. Our paper follows the QE literature and features frictions on financial
intermediaries. QE transmits through intermediaries and impacts the real economy via investment. In
contrast, Cui and Sterk (2021) follow more closely the HANK literature, with two types of assets households
can hold. The main mechanism through which QE works in their model is through household marginal
propensities to consume out of two types of assets, not via intermediaries or through firm investment.
2
We develop a quantitative general equilibrium model with household heterogeneity and
scope for QE to matter. Households face uninsurable idiosyncratic unemployment ris and
endogenously supply labor. They may save via short-term deposits with financial interme-
diaries, subject to a borrowing constraint, and receive dividends from their ownership in
production firms and financial intermediaries. Financial intermediaries engage in maturity
transformation, standing between households who save via short-term deposits, and produc-
tion firms who float long-term debt to finance investment. Financial intermediaries face an
endogenous leverage constraint, and production firms are required to finance a fraction of
their investment by issuing long-term bonds. Prices and nominal wages are sticky. Central
bank purchases of long-term assets can ease the leverage constraint facing intermediaries,
resulting in lower interest rate spreads and more investment. We refer to an exogenous
increase in central bank long-term asset holdings as a QE shock.
In our benchmark specification, we assume that all households receive the same dividend
payout each period. The responses of aggregate variables to a QE shock are nearly identical to
a representative agent (RANK) version of the model, even though the HANK version features
substantial wealth inequality due to uninsurable employment risk and a borrowing constraint.
The only noticeable difference is the consumption response of the very poorest households
in the HANK version, which increases sharply after a QE shock. But this distributional
difference has little impact on aggregate variables.
We consider robustness of our results with respect to both the micro- and macro- distri-
butions of wealth. First, regarding the micro distribution, we allow a more general dividend
distribution rule, in which dividends vary, potentially non-linearly, with household wealth.
We explore the implications of this distribution rule for popular inequality metrics, such
as the Lorenz Curve and the Gini Coefficient. With a significant gap between dividends
received by the richest and poorest households, and sufficient non-linearity in the relation-
ship between dividend receipt and wealth, our model can generate more wealth inequality
compared to our benchmark specification. However, different degrees of micro-level wealth
3
inequality matter little for aggregate dynamics. Regardless of how we specify the dividend
distribution rule, we find that the impulse responses of aggregate variables to a QE shock
are remarkably similar, and in turn almost identical to a RANK version of the model.
Next, we investigate the extent to which macro parameterizations related to the wealth
distribution influence the aggregate transmission of QE shocks. When we parameterize
the model so that a higher fraction of the population is unemployed in each period, many
more households are located at or near the borrowing constraint compared to our baseline
specification. This results in the aggregate effects of a QE shock being slightly bigger.
These differences are nevertheless not economically large, and are only visibly noticeable for
very high unemployment rates. We then investigate whether the duration of unemployment
spells matters for the aggregate transmission of QE shocks and find it is almost completely
irrelevant. We also examine the role of the unemployment benefit paid out to unemployed
households. Smaller or larger values of this parameter have modest implications for the
stationary wealth distribution, but matter little for the aggregate effects of QE. Finally, we
study the sensitivity of our results to households’ risk aversion. This parameter has little
effect on how QE impacts the economy.
There are two potentially important takeaways from our quantitative exercises. The
first is that there seems to be little gained by formally modeling household heterogeneity
if one is interested in is the aggregate effects of a QE shock. Our finding that RANK is a
good approximation to a substantially more complicated and numerically more demanding
HANK model is consistent with a recent paper by Debortoli and Gali (2022), who argue
that idiosyncratic income uncertainty is unimportant for aggregate fluctuations. Another
important takeaway from our analysis is that there seems to be little connection between
various inequality metrics and aggregate dynamics in response to a QE shock. Much of
the existing literature uses moments such as the Gini coefficient as summary statistics for
inequality. To the extent to which one is only interested in aggregate dynamics, our results
suggest that this focus on inequality metrics might be misplaced.
4
In addition to these substantive issues, our paper also makes a methodological con-
tribution. Though our model features idiosyncratic income risk, wealth inequality, and a
borrowing constraint, we are able to solve the model using perturbation methods in Dynare,
a popular program for solving, simulating, and estimating RANK models. Our paper is sim-
ilar in this respect to Winberry (2018), who also solves a heterogeneous agent model with
perturbation methods in Dynare. Substantively, our model features nominal rigidities and
other frictions common in the New Keynesian literature, whereas his model fits into a real
business cycle framework. Methodologically, we depart from him in that we follow Young
(2010) to approximate the cross-sectional distribution with a non-parametric histogram,
whereas Winberry (2018) follows Algan et al. (2008) to approximate this distribution within
a parameteric family. The advantage of our approach is that it does not involve numerical
optimization, which slows the calculation when done repeatedly and does not guarantee con-
vergence. Our method is not limited to the QE application on which we focus in this paper,
nor is it specific to the exact form of household heterogeneity.
The remainder of the paper is organized as follows. Section 2 lays out our model. Section 3
discusses our method for solving the model. Section 4 compares and contrasts impulse
responses to an exogenous QE shock with and without household heterogeneity. Section 5
discuss our model’s implications for popular inequality metrics and considers a more general
form of the dividend distribution rule to study how that affects the aggregate dynamics in
response to a QE shock. Section 6 considers changing macro parameters and investigates
the extent to which they matter for aggregate dynamics in response to a QE shock. The
final section concludes.
2 Model
Our model features financial frictions, a banking sector, and has scope for central bank
asset purchases to matter. In addition, households are heterogeneous and face uninsurable
5

unemployment risk. In this section,we provide detail on key elements of the model and
relegate remaining details to Appendix A.
2.1 Households
The household sector is similar to Krusell and Smith (1998), except that labor supply is
endogenous. There are a continuum of households indexed by j ∈ [0, 1]. Each maximizes
the present discounted value of lifetime flow utility:
E
0
∞
X
t=0
β
t
log c
j,t
− χ
l
1+η
j,t
1 + η
!
, (2.1)
where c
j,t
and l
j,t
are an individual household’s consumption and labor supply. β ∈ (0, 1) is
a discount factor, χ > 0 is a scaling parameter, and η is the inverse Frisch elasticity.
Each household faces an exogenous idiosyncratic labor productivity shock, ε
j,t
∈ {0, 1}.
This productivity shock can be interpreted as an employment shock, where ε
j,t
= 0 indicates
unemployed and consequently l
j,t
= 0, while ε
j,t
= 1 means that the household will earn
a positive market wage and will hence choose to work, l
j,t
> 0. ε
j,t
evolves stochastically
according to a two-state Markov process with the transition matrix
p(ε
j,t+1
= 0|ε
jt
= 0) p(ε
j,t+1
= 1|ε
jt
= 0)
p(ε
j,t+1
= 0|ε
jt
= 1) p(ε
j,t+1
= 1|ε
jt
= 1)
=
p 1 − p
U
1−U
(1 − p) 1 −
U
1−U
(1 − p)
. (2.2)
The aggregate unemployment rate is U = p(ε
j,t
= 0) and is fixed. Total labor supply is
L
t
=
R
1
0
l
j,t
dj.
Household j saves via deposits, d
j,t
, with financial intermediaries, which earn the gross
interest rate, R
d
t
, from t to t + 1. Deposits are the only asset the household can accumulate.
A household faces the following flow budget constraint:
6

d
j,t
=
R
d
t−1
Π
t
d
j,t−1
+ mrs
t
[(1 − τ)l
j,t
ε
j,t
+ µ(1 − ε
j,t
)] − c
j,t
− T
t
+ div
j,t
− X, (2.3)
where Π
t
is the gross inflation rate, mrs
t
is the real wage, τ is a tax rate on labor income,
µ × mrs
t
is an unemployment benefit, T
t
is a lump-sum tax, and X is a real transfer paid
out to new financial intermediaries, to be discussed below. div
j,t
is a dividend transfer from
all firms. This dividend is taken as given by households; we will discuss how it is distributed
across agents in Section 4 and Section 5. d
j,t
, c
j,t
,and l
j,t
are endogenous choice variables.
Each household faces a borrowing constraint and a constraint on its time endowment:
d
j,t
≥ d (2.4)
l
j,t
≤
¯
l. (2.5)
The first order conditions are
c
−1
j,t
≥ βR
d
t
E
t
c
−1
j,t+1
Π
t+1
(2.6)
l
η
j,t
≤
(1 − τ)mrs
t
χc
j,t
. (2.7)
The equalities hold when the constraints in (2.4) and (2.5) do not bind.
2.2 Labor Market
We introduce wage rigidity into our model via labor unions. Unions are indexed by h ∈
[0, 1]. These unions purchase labor from households at real wage mrs
t
, repackage it into
L
d,t
(h), and sell it to a representative labor contractor at nominal wage, W
t
(h). The labor
contractor combines differentiated labor into final labor available for production, L
d,t
via a
CES technology. Final labor is sold to a representative production firm at nominal wage,
7
W
t
.
Unions are subject to a Calvo-style nominal rigidity. Each period, a union can adjust
its wage, W
t
(h), with probability 1 − ϕ
w
, where ϕ
w
∈ [0, 1]. Non-updated wages can be
indexed to lagged aggregate inflation via the parameter γ
w
∈ [0, 1]. This setup gives rise to
a conventional wage Phillips curve. See the Appendix for details.
2.3 Production
There are four different types of firms in our model. A representative capital goods producer
transforms raw investment goods into new physical capital subject to a convex adjustment
cost. A competitive final good producer aggregates retail output into final output via a
CES technology and sells it at nominal price, P
t
. A continuum of retail firms, indexed
by f ∈ [0, 1], repackage wholesale output and sell it to the final good producer at P
t
(h).
Retailers have market power and are subject to a Calvo-style nominal rigidity, updating
their prices with probability 1 − ϕ
p
each period. Non-updated prices can be indexed to
lagged inflation via the parameter γ
p
∈ [0, 1]. The representative wholesale firm accumulates
its own capital, purchases new capital from the capital goods producer, and hires labor from
the labor contractor. It produces wholesale output, Y
m,t
, from capital and labor, and sells
this output to retail firms at P
m,t
. The wholesale firm can choose the intensity with which
it utilizes physical capital, u
t
, the cost of which is faster depreciation.
With the exception of the wholesale firm, the production side of the model is reasonably
standard, and details are relegated to an appendix. The wholesale firm accumulates its own
physical capital, K
t
. It purchases new physical capital,
b
I
t
, from the capital goods producer
at nominal price P
k
t
. We require that the wholesale firm finance a fraction, ψ ∈ [0, 1], of
its purchases of new physical capital by issuing long-term bonds. As in Woodford (2001),
these long-term bonds take the form of perpetuities with decaying coupon payments. Let
κ ∈ [0, 1] denote the decay parameter for coupon payments. A bond in period t is sold for
Q
t
dollars and obligates the issuer to a coupon payment of one dollar in t + 1, κ dollars
8
in t + 2, κ
2
dollars in t + 3, and so on. The total nominal coupon liability due in t from
all past issuances is denoted by F
m,t−1
; new issuance of bonds in t is therefore denoted by
F
m,t
− κF
m,t−1
, which generates Q
t
dollars for the issuer. The “loan in advance” constraint
facing the wholesale firm is:
ψP
k
t
b
I
t
≤ Q
t
(F
m,t
− κF
m,t−1
). (2.8)
Equation (2.8) distorts standard first order conditions related to capital investment and bond
issuance. It therefore generates “investment” and “financial” wedges. Fluctuations in these
wedges are the mechanism through which QE-type policies transmit to the real economy.
2.4 Financial Intermediaries
Financial intermediaries are structured similarly to Gertler and Karadi (2011, 2013), and
Sims and Wu (2021a,b). Each period there is a fixed mass of intermediaries indexed by i.
Intermediaries finance themselves with net worth, N
i,t
, and deposits taken from households,
D
i,t
. Each period, a fraction 1 − σ, with σ ∈ [0, 1], stochastically exit and return their net
worth to their household owner. They are replaced by an equal number of new intermediaries
that begin with real start up funds of X given to them by their household owner.
Intermediaries hold privately issued bonds, F
i,t
; government issued nominal bonds, B
i,t
;
and interest-bearing reserves, RE
i,t
, which are held on account with the central bank. Gov-
ernment bonds are structured similarly to private long-term bonds and are priced at Q
B,t
.
The balance sheet condition of a typical intermediary is:
Q
t
F
i,t
+ Q
B,t
B
i,t
+ RE
i,t
= D
i,t
+ N
i,t
(2.9)
A financial intermediary accumulates net worth until stochastically exiting. Net worth
9

for surviving intermediaries evolves according to:
N
i,t
=
R
F
t
− R
d
t−1
Q
t−1
F
i,t−1
+
R
B
t
− R
d
t−1
Q
B,t−1
B
i,t−1
+
R
re
t−1
− R
d
t−1
RE
i,t−1
+R
d
t−1
N
i,t−1
(2.10)
R
re
t−1
is the (gross) interest rate on reserves, which is set by the central bank and known at
t−1. R
d
t−1
is the deposit rate, which is determined in equilibrium. (R
F
t
−R
d
t−1
), (R
B
t
−R
d
t−1
),
and (R
re
t−1
−R
d
t−1
) are, respectively, the excess returns from holding private bonds, government
bonds, and reserves relative to the cost of funding via deposits. The term R
d
t−1
N
i,t−1
measures
the cost-savings from financing via net worth as opposed to deposits. R
F
t
and R
B
t
are the
realized holding period returns on private and government bonds and satisfy:
R
F
t
=
1 + κQ
t
Q
t−1
(2.11)
R
B
t
=
1 + κQ
B,t
Q
B,t−1
(2.12)
The objective of an intermediary is to maximize its expected terminal net worth, where
discounting is by the stochastic discount factor for households who are not at the borrowing
constraint
2
Λ
t,t+1
=
Π
t+1
R
d
t
. (2.13)
Consider the problem of an intermediary continuing after period t. There is a 1 − σ
probability that it will exit after t + 1, a (1 − σ)σ probability that it will exit after t + 2, and
so on. Accordingly, its objective is
V
i,t
= max (1 − σ)E
t
∞
X
j=1
σ
j−1
Λ
t,t+j
n
i,t+j
, (2.14)
where n
i,t
= N
i,t
/P
t
is real net worth, with P
t
the price of final output.
2
Note that while consumption levels will differ for unconstrained households, since (2.6) will hold with
equality, they all have the same stochastic discount factor.
10

A financial intermediary faces a costly enforcement constraint as in Gertler and Karadi
(2011, 2013). A financial intermediary can choose to abscond with some assets at the end of a
period rather than continuing as an intermediary. If an intermediary does this, depositors can
recover a fraction of the intermediary’s assets, with the intermediary retaining the rest. For
depositors to be willing to lend to intermediaries, it must not be optimal for the intermediary
to divert funds in this way, which we refer to as going into bankruptcy. Accordingly:
V
i,t
≥ θ(Q
t
f
i,t
+ ∆Q
B,t
b
i,t
) (2.15)
In (2.15), the right hand side of the inequality represents the (real) funds that a financial
intermediary can keep should it choose to enter bankruptcy, while the left hand side is the
value of continuing as an intermediary.
3
Should it choose to divert, an intermediary can keep
a fraction of its private bonds, θ, and a fraction of government bonds, θ∆, where 0 ≤ ∆ ≤ 1.
We assume that the third type of asset held by intermediaries – reserves – is fully recoverable
by depositors in the event of bankruptcy.
All financial intermediaries will behave in the same way with identical optimality condi-
tions. These are
E
t
Λ
t,t+1
Ω
t+1
Π
−1
t+1
R
F
t+1
− R
d
t
=
λ
t
1 + λ
t
θ (2.16)
E
t
Λ
t,t+1
Ω
t+1
Π
−1
t+1
R
B
t+1
− R
d
t
=
λ
t
1 + λ
t
θ∆ (2.17)
E
t
Λ
t,t+1
Ω
t+1
Π
−1
t+1
R
re
t
− R
d
t
= 0, (2.18)
where
Ω
t
= 1 − σ + σθϕ
t
(2.19)
ϕ
t
=
1 + λ
t
θ
t
E
t
[Λ
t,t+1
Ω
t+1
Π
−1
t+1
]R
d
t
. (2.20)
3
f
i,t
= F
i,t
/P
t
and b
i,t
= B
i,t
/P
t
are real private and government bond holdings, respectively.
11

(2.16) - (2.18) are the key equilibrium conditions. λ
t
≥ 0 is the multiplier on the costly
enforcement constraint. If this constraint does not bind, then to first order expected returns
on all three types of assets must equal the cost of funds (i.e. the deposit rate). If the costly
enforcement constraint binds, then there will be excess returns of long-term private and
public bonds over the deposit rate. Because reserves are fully recoverable in the event of
liquidation, arbitrage requires that the interest rate on deposits equal the interest rate on
reserves. (2.19) is an auxiliary variable introduced to simplify the analysis.
The value of an intermediary satisfies
V
i,t
= θϕ
t
n
i,t
. (2.21)
When the constraint in (2.15) binds,
ϕ
t
=
Q
t
f
i,t
+ ∆Q
B,t
b
i,t
n
i,t
, (2.22)
which is an endogenous leverage ratio, whose equilibrium condition is in (2.20). The con-
straint makes the financial intermediary less levered than it would find optimal. This en-
dogenous leverage constraint is ultimately what can give rise to excess returns.
One can show from (2.20) that:
θϕ
t
≥ 1 + λ
t
(2.23)
If (2.15) does not bind, then λ
t+j
= 0 for all j, which implies that θ
t
ϕ
t
= 1.
4
Intuitively,
this means that net worth is as valuable to a household as to an intermediary. In this case,
returns on all assets would be equal. Hence, whether an intermediary invests in F
i,t
, D
i,t
or
RE
i,t
would be irrelevant. When the costly enforcement constraint binds, then λ
t
> 0 and
θϕ
t
is larger than one. In this case, there exist excess returns on holding long-term assets
4
In this circumstance, Ω
t
= 1.
12
(private and government bonds).
2.5 Fiscal authority
A fiscal authority finances its expenditure by levying lump sum taxes and a labor income tax
on households, from receipt of a transfer, T
cb,t
, from the central bank, and by issuing long-
term bonds. Its expenditure includes purchases of output, G
t
, and unemployment benefits.
For simplicity, we assume that the government has a fixed real stock of long-term bonds
issued,
¯
b
G
. The government’s budget constraint is:
G
t
+ Π
−1
t
¯
b
G
+ mrs
t
µU = T
t
+ T
cb,t
+ Q
B,t
¯
b
G
(1 − κΠ
−1
t
) + τmrs
t
L
t
(2.24)
2.6 Monetary policy
The central bank controls the interest on reserves R
re
t
, which evolves according to a Taylor
(1993)-type interest rate rule:
ln R
re
t
= (1 − ρ
r
) ln R
re
+ ρ
r
ln R
re
t−1
+
(1 − ρ
r
) [ϕ
π
(ln Π
t
− ln Π) + ϕ
y
(ln Y
t
− ln Y
t−1
)] + σ
r
ϵ
r,t
, (2.25)
where 0 ≤ ρ
r
< 1, ϕ
π
> 1, and ϕ
y
≥ 0. ϵ
r,t
is a policy shock. We do not formally analyze
the implications of the ZLB in our analysis, but it would be straightforward to do so.
In addition to setting the interest rate on reserves, the central bank can buy and sell long-
term bonds (either privately issued bonds or government bonds). It finances these holdings
via reserves, which are held in the banking system. The central bank’s balance sheet, in
nominal terms, is:
Q
t
F
cb,t
+ Q
B,t
B
cb,t
= RE
t
(2.26)
13
The central bank’s remittance to the fiscal authority amounts to
T
cb,t
= (1 + κQ
t
) Π
−1
t
f
cb,t−1
+ (1 + κQ
B,t
) Π
−1
t
b
cb,t−1
− R
re
t−1
Π
−1
t
re
t−1
(2.27)
We model a QE shock as an exogenous and persistent change in central bank bond
holdings. In particular, we assume that real central bank holdings of privately issued bonds,
f
cb,t
, follow a stationary AR(1) process (and similarly for holdings of real government bonds,
b
cb,t
):
ln f
cb,t
= (1 − ρ
f
)f
cb
+ ρ
f
ln f
cb,t−1
+ σ
f
ϵ
f,t
, (2.28)
where 0 ≤ ρ
f
< 1 and f
cb
denotes steady state real bond holdings.
If financial intermediaries are unconstrained (i.e. (2.15) does not bind), then fluctuations
in central bank bond holdings are irrelevant. But if intermediaries are constrained, then
increases in central bank bond holdings ease the endogenous leverage constraint, resulting in
higher long-term bond prices (equivalently, lower long-term yields). This filters through to
the real economy by relaxing the loan in advance constraint on wholesale producers, leading
to more investment and higher aggregate demand.
3 Solution Method and Calibration
In this section, we outline our solution method and discuss the parameterization of our
model.
3.1 Solution Method
We solve our model using perturbation methods with the popular software Dynare. Com-
pared to a global solution, perturbation methods can accommodate a large number of state
variables and require less computational time. Though it is standard practice to solve a
14

RANK model using Dynare, it is not straightforward to do so when there is household
heterogeneity.
Solving the aggregate part of the model via Dynare is straightforward. The key step
we take is to map the equilibrium conditions of individuals’ policy functions and the cross-
sectional distribution into Dynare. We approximate the conditional expectation, the right-
hand side of (2.6), using Chebyshev polynomials (see, for example, Judd 1998):
5
βR
d
t
E
t
c
−1
t+1
Π
t+1
≡ T(d
t−1
, ε
t
) ≈ exp
(
N
X
n=0
θ
n,t
(ε
t
)T
n
(ξ(d
t−1
))
)
(3.1)
where T
n
are Chebyshev polynomials and θ
n,t
are loadings. T(d
t−1
, ε
t
) gives the inverse of
consumption in period t if the borrowing constraint does not bind. We then solve for the
policy function for deposits, labor, and consumption as follows:
d
t
= max
(
R
d
t−1
Π
t
d
t−1
+ mrs
t
[(1 − τ )l
t
ε
t
+ µ(1 − ε
t
)] − T(d
t−1
, ε
t
)
−1
− T
t
+ div
t
− X, d
)
(3.2)
l
t
= min
(
(1 − τ )mrs
t
χc
t
1
η
,
¯
l
)
(3.3)
c
t
=
R
d
t−1
Π
t
d
t−1
+ mrs
t
[(1 − τ )l
t
ε
t
+ µ(1 − ε
t
)] − d
t
− T
t
+ div
t
− X (3.4)
Iterating the policy functions one period forward, we can further express c
t+1
as a function
of T(d
t
, ε
t+1
) and hence θ
n,t+1
. Therefore, (3.1) becomes the dynamic equation for θ
n,t
. For
details, see Appendix B.
Next, we update the cross-sectional distribution from t to t+1. We use the non-parametric
method proposed by Young (2010) by approximating the joint distribution p(d
t
, ε
t+1
) with
a histogram over the grid {d
m
}
M
m=0
and ε
t+1
= {0, 1}. The transition dynamics for the
cross-sectional distribution are given by:
p(d
t
, ε
t+1
) =
X
ε
t
X
d
t−1
p(d
t
|d
t−1
, ε
t
)p(ε
t+1
|ε
t
)p(d
t−1
, ε
t
), (3.5)
5
For brevity, we drop j subscript hereafter.
15

where p(ε
t+1
|ε
t
) is given in (2.2).
We know d
t
(d
t−1
, ε
t
) from the policy function. However, even with d
t−1
on a discrete
grid, d
t
does not necessarily fall on a grid point. We follow Young (2010) and approximate
p(d
t
|d
t−1
, ε
t
) with the d
m
grid: find the two neighboring grids d
m
′
, d
m
′
+1
that are closest to
d
t
, where m
′
= 0, ...., M − 1. Assign weights to them using
p(d
t
= d
m
′
|d
t−1
= d
m
, ε
t
) = 1 −
d
t
− d
m
′
d
m
′
+1
− d
m
′
p(d
t
= d
m
′
+1
|d
t−1
= d
m
, ε
t
) =
d
t
− d
m
′
d
m
′
+1
− d
m
′
. (3.6)
With the transition probabilities in (3.6) and (2.2), (3.5) characterizes the dynamics equa-
tions for the joint probability p(d
t
, ε
t+1
). See Appendix C for the full set of equilibrium
conditions that we feed into Dynare.
For the stationary equilibrium without aggregate shocks, we solve a fixed-point problem
over aggregate deposits, d, and labor supply, L (aggregate consumption is then determined
given the resource constraint). We proceed in steps. First, given guesses of d and L, we
can compute stationary equilibrium values of all aggregate variables. Then we solve for the
stationary equilibrium values of the Chebyshev coefficients; this step is also a fixed point
problem. Third, we solve the stationary distribution p(d, ε) by iterating (3.5) forward on
the discretized grid until convergence. Once we have the distribution from this step and
the policy functions from the Chebyshev step, we can compute updated values of aggregate
deposits,
e
d, and labor,
e
L. We then iterate over these steps until d ≈
e
d and L ≈
e
L. For
details of solving the stationary equilibrium, see Appendix D.
Our solution method is related to Winberry (2018). He also proposes a methodology
to solve a model with heterogeneous agents in Dynare. The main difference relative to our
approach is that he approximates the cross-sectional distribution following Algan, Allais and
Haan (2008), who use a parametric family. This methodology requires a large number of
numerical optimizations when solving the stationary equilibrium. The optimization routines
16

do not guarantee convergence and the computational burden is high. The numerical behavior
of their approach becomes problematic when the distribution is far away from a normal
distribution, which is the case for our application.
We, instead, follow Young (2010), who uses a histogram over a fixed grid to construct
the cross-sectional distribution. In his approach, updating the approximate cross-sectional
distribution is analytical and does not require numerical optimization. Therefore, it works
well with highly skewed distributions like the ones in our paper. One downside of Young’s
(2010) approach is to accurately approximate the distribution, it requires a large number
of state variables in Dynare, which makes adding additional idiosyncratic states difficult, if
not infeasible. Our solution method is also related to Reiter (2009) in the sense that he also
approximates the cross-sectional distribution with a histogram and employ a perturbation
method.
3.2 Calibration
Table 1 lists the parameter values that are unique to the HANK setup. We set U = 0.05,
which is the fraction of households with low productivity (ε = 0), and hence can be inter-
preted as the aggregate unemployment rate. Conditional on being unemployed, the prob-
ability of remaining unemployed, p, is 0.5. This means that the expected unemployment
duration is two quarters. The scaling parameter governing the disutility of labor, χ, is cho-
sen so that steady state labor supply in a representative agent version of the model would
be L
RANK
= 0.95.
6
The unemployment benefit is set to 40 percent the wage, µ = 0.4, which
follows Shimer (2005). The labor income tax rate is 30% following Kaplan et al. (2018).
d = 0 implies agents are not allowed to borrow, and
¯
l = 1.5 implies the time endowment for
work is 150% of l
RANK
= 1. If we interpret l
RANK
= 1 to eight hours a day,
¯
l = 1.5 means
the maximum amount someone can work is 12 hours a day. For other parameters, we follow
the calibration from Sims and Wu (2021a); see details in Table E.1 of Appendix E.
6
This could be interpreted as 95 percent of the population supplying l
RANK
= 1 unit of labor each, which
17

Table 1: Calibration of HANK parameters
Parameters Value Target Description
U 0.05 Fraction unemployed
p 0.5 unemployment duration two quarters Probability of staying unemployed
χ L
RANK
= 1 − U Labor disutility scaling parameter
µ 0.4 Unemployment benefit / wage
τ 0.3 Labor income tax rate
d 0 Borrowing constraint
¯
l 1.5 Time endowment
4 HANK vs RANK
In this section, we compare and contrast impulse responses to a QE shock under both a
RANK and a baseline HANK specification.
7
In the baseline HANK model, we assume
dividends are equally distributed across households; we explore the implications of different
distribution rules in Section 5.
Even with this equal distribution rule, there remains significant household wealth het-
erogeneity that arises from uninsurable employment/productivity risk. Figure 1 plots the
stationary distribution of wealth across households, where wealth is normalized by the av-
erage steady state labor income. We do so for both unemployed households (solid blue line)
and employed households (dashed red line). Few households are located at the borrowing
constraint in the stationary distribution.
8
Nevertheless, most households are relatively poor,
with the distribution of wealth highly right skewed. There are a decent number of house-
holds who are quite wealthy and far away from the borrowing constraint. The distribution of
unemployed households is slightly towards the left of that for employed households, implying
that the former are, on average, less wealthy than the latter.
Figure 2 plots impulse responses to a persistent, private QE shock. The shock is scaled to
is comparable to the targeted 5 percent unemployment rate in the HANK specification.
7
The representative household of the RANK model is standard; we discuss the problem facing the house-
hold, and the associated first order optimality conditions, in Appendix F.
8
We do not include the borrowing constraint in the plot because its probability density is infinity by
construction.
18
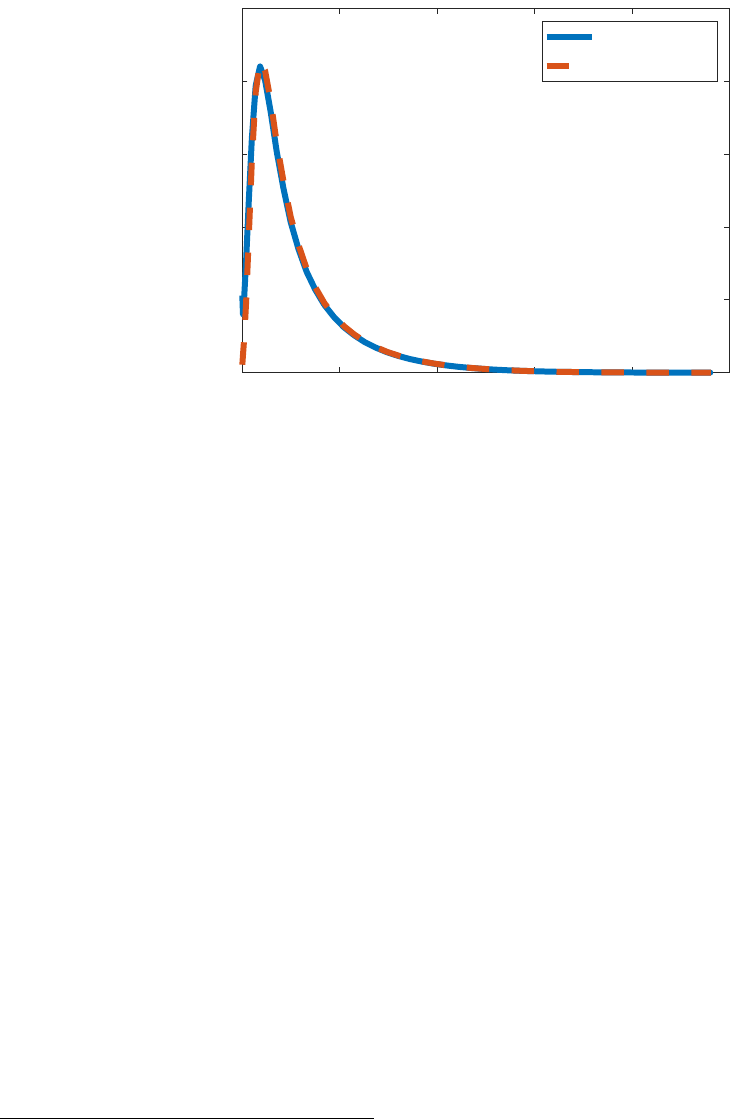
Figure 1: Stationary Distribution
0 20 40 60 80 100
deposit/labor income
0
0.02
0.04
0.06
0.08
0.1
unemployed
employed
Notes: Blue solid line: unemployed households; red dashed line: employed households. We do not plot the
mass for constrained households. The x-axis measures the ratio between deposits and average steady state
labor income.
represent a four-percent increase in central bank bond holdings.
9
The solid blue lines show
responses under a RANK version of the model, while the dashed red lines are responses
generated from the HANK specification.
The responses of aggregate variables to a shock to central bank bond-holdings in the
RANK specification (blue) are similar to Sims and Wu (2021a). Bond purchases ease the
leverage constraint on intermediaries, which results in declining interest rate spreads. This,
in turn, results in more investment. Higher aggregate demand results in output, labor, and
inflation all rising temporarily.
For all aggregate variables, the responses under the HANK specification (dashed red lines)
are qualitatively and quantitatively similar to the RANK version of the model. Some vari-
ables, including consumption, output, inflation, and labor, rise slightly more in the HANK
specification on impact, but these differences are small and short-lived.
9
This shock generates a similar-sized response of output as to a conventional shock to the policy rule
for the short-term interest rate with a size of 25 basis points; see Figure G.1 in the appendix. As noted in
Appendix E, we assume an autoregressive parameter of 0.8. Responses to a public QE shock (i.e. a purchase
of long-term government bonds, instead of privately-issued bonds), would produce the same-shaped impulse
responses, albeit at a smaller scale.
19
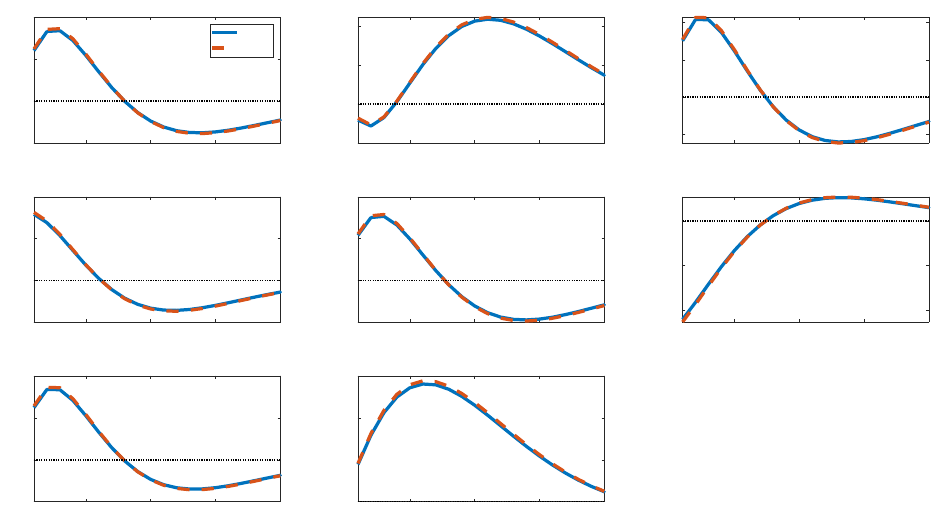
Figure 2: Impulse responses to a QE shock: RANK vs. HANK
5 10 15 20
-0.5
0
0.5
1
output
RANK
HANK
5 10 15 20
-0.1
0
0.1
0.2
consumption
5 10 15 20
-2
0
2
4
investment
5 10 15 20
-0.05
0
0.05
0.1
inflation
5 10 15 20
-0.05
0
0.05
0.1
policy rate
5 10 15 20
-0.2
-0.1
0
corp. bond spread
5 10 15 20
-0.5
0
0.5
1
labor
5 10 15 20
0
0.5
1
1.5
deposit
Notes: This figure plots the impulse responses of aggregate variables under a 4% QE shock. The blue solid
lines are for the RANK model, and the red dashed lines are for the HANK model. The x-axis is time in
quarters, and the y-axis is the percentage change from steady state.
We next inspect the reasons for the slight differences in aggregate responses in the HANK
vs. RANK setups. Figure 3 plots the first-period responses of individual choice variables to
a QE shock against the percentile of the wealth distribution. We do so both for a RANK
version of the model (solid blue) and our baseline HANK version (dashed red lines). In the
left panel, we plot the first-period responses across the full wealth distribution. To increase
readability, in the right panels we zoom in on responses for households in the bottom one
percent of the wealth distribution. In the RANK model, all households behave identically,
so the figures simply show flat lines.
For all but the very poorest households, the first-period individual responses for con-
sumption, deposits, and labor are almost identical to the RANK counterpart. The poorest
households, in contrast, behave quite differently. These households increase their consump-
tion and deposits, and reduce their labor supply, following a QE shock. What drives these
results? Households located near the borrowing constraint are working more and consuming
20
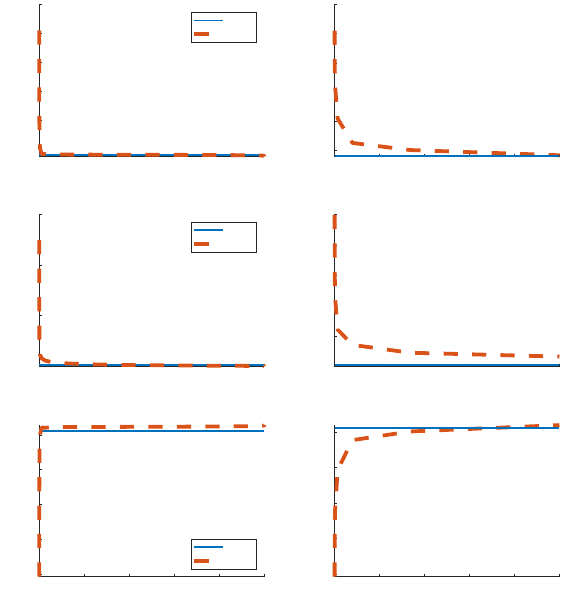
Figure 3: First period individual responses to a QE shock: RANK vs. HANK
0 20 40 60 80 100
0
0.2
0.4
0.6
0.8
1
consumption
RANK
HANK
0 20 40 60 80 100
0
20
40
60
deposit
RANK
HANK
0 20 40 60 80 100
deposit percentile
-0.2
0
0.2
0.4
0.6
labor
RANK
HANK
0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
1
consumption
0 0.2 0.4 0.6 0.8 1
0
10
20
30
40
50
deposit
0 0.2 0.4 0.6 0.8 1
deposit percentile
-0.2
0
0.2
0.4
0.6
labor
Notes: This figure plots the impulse responses of (employed) individual decision variables (consumption,
deposits, and labor supply) in the period when a 4% positive QE shock hits. The blue solid lines and red
dotted lines are for the RANK and baseline HANK models, respectively. The x-axis measures the wealth
fraction from poor to rich, and the y-axis is the percentage relative to steady state. The left panel plots
first-period responses across the full wealth distribution, while the right panel zooms in on the bottom one
percent.
less than they would find optimal absent a borrowing constraint. The extra income from
the QE shock allows them to move towards the unconstrained optimal allocation. They also
take advantage of the income windfall by significantly increasing deposits, which moves them
further from the borrowing constraint. The fact that only few households behave differently
helps to explain why there is very little difference in the aggregate responses to a QE shock
in the HANK and RANK models.
We conclude from the analysis in this section that the aggregate responses to an expan-
sionary QE shock are quite similar in the HANK and RANK specifications, at least for the
equal distribution rule. Though there are micro-level differences in behavior for the poorest
households, overall they do not have much impact on the dynamics of macro aggregates.
21

In the next sections, we investigate whether this conclusion holds up when dividends are
distributed differently across households or when we vary some macro parameters.
5 Implications of the Micro-Distribution of Wealth
In this section, we explore the implications of the micro wealth distribution for our main
results discussed in Section 4. First, we specify a more general distribution for dividends
in Subsection 5.1. Next, we show the role of different rules for popular metrics of wealth
inequality, such as the Lorenz Curve or the Gini Coefficient in Subsection 5.2. Finally, in
Subsection 5.3, we circle back to the main question of interest of the paper and examine how
the micro wealth distribution influences the macro responses to a QE shock.
5.1 Distribution Rules
In Section 4, we assumed dividends from production firms are equally distributed among
households. We now assume a more general dividend distribution rule:
div
j,t
div
t
= a
t
+ b
t
d
ϑ
j,t−1
. (5.1)
In (5.1), d
j,t−1
corresponds to household j’s wealth level (in the form of deposits). a
t
and b
t
are time-varying parameters that govern how household j’s share of dividends vary with its
wealth. ϑ ≥ 1 allows for a household’s dividends to vary non-linearly with its own wealth.
Taking ϑ as given, the parameters a
t
and b
t
are chosen so that the following two equations
hold each period:
Z
1
0
a
t
+ b
t
d
ϑ
j,t−1
dj = 1, (5.2)
a
t
+ b
t
¯
d
ϑ
a
t
+ b
t
d
ϑ
= n. (5.3)
22

(5.2) imposes that the sum of dividends received by individual households must equal aggre-
gate dividends each period. (5.3) says that the ratio of the dividends received by the richest
household (i.e. the household on the largest point on our deposit grid,
¯
d) to the dividends
received by the poorest household (i.e. the household on the lowest point on our deposit
grid, d = 0) is equal to n.
10
In Section 4, we implicitly imposed n = 1.
11
In this section, we
experiment with different values of n and ϑ.
To get a better sense of how different values of n and ϑ impact households in the model,
Figure 4 plots the relative weight of dividends received by individuals with different wealth
levels in the model’s stationary distribution,
a+bd
ϑ
j
a
=
1 +
b
a
d
ϑ
j
, where we take the poorest
household, with d = 0, as the reference point. By construction, the poorest household always
has a relative weight of unity, and the richest household always has a relative weight of n.
The notation we use is that the letter standards for ϑ; we consider three values, L for linear
(ϑ = 1), S for squared (ϑ = 2), and C for cubic (ϑ = 3). The number after the letter
corresponds to the assumed value of n. We consider values of n = 10 and n = 100; our
baseline case, which we label “HANK,” can also be labeled L1 (ϑ = 1 (linear) and n = 1).
The left panel considers linear distribution schemes (ϑ = 1), while the right panel compares
the linear distribution scheme to the squared and cubic schemes by fixing n = 10.
In our baseline HANK specification (blue line, left panel) all households receive the same
dividends, and the relative weights are therefore constant at unity. When we increase n but
remain in the linear specification, all other households receive a higher share of dividends
relative to the poorest household. The relative weight of a household at a fixed percentile in
the wealth distribution is bigger the larger is n.
Even though a larger n means the richest household receives more dividends than the
poorest, the linear scheme has the effect of allocating more dividends to the middle of the
10
Note that we solve the model with fixed grid points for deposits, so
¯
d is always the same. In other words,
the wealth gap between the richest and poorest household is always fixed.
11
Focusing on (5.3), when n = 1, given that d ̸=
¯
d it must be the case that b
t
= 0. But then from (5.2),
it follows that a
t
= 1. When n ̸= 1, then b
t
̸= 0 and will be time-varying. This also means that a
t
̸= 1 and
will also be time-varying.
23
Figure 4: Relative distribution weight
0 20 40 60 80 100 120 140
deposit
1
20
40
60
80
100
HANK
L10
L100
0 20 40 60 80 100 120 140
deposit
1
5
10
L10
S10
C10
Notes: This figure plots the relative weight of dividend obtained by people at different wealth level at the
stationary distribution (1 +
b
a
d
ϑ
j
). The blue solid lines, red dotted lines, and the yellow dashed lines on
the left(right) column are for the baseline HANK(L10), L10(S10), and L100(C10) models, respectively. The
x-axis is the wealth level, and the y-axis is the relative weight.
wealth distribution when n is bigger. This has the effect of reducing overall inequality. This
implication is illustrated in the left panel of Figure 5, which plots the stationary wealth
distribution from our model under the same dividend distribution rules as the left panel of
Figure 4. From Figure 5, we can see that higher values of n shift more mass in the stationary
distribution to the right, although this mass remains concentrated away from the far-right
tail.
In the right panel of Figure 4, we compare a linear distribution scheme (solid blue line)
to squared and cubic schemes (dotted-red and dashed-orange lines, respectively). While
the endpoints are the same in all cases, more curvature will increase inequality. We show
this result with the right panel of Figure 5. Relative to a linear distribution scheme, more
curvature has the effect of concentrating much more mass near the borrowing constraint,
which has the effect of increasing overall wealth inequality. For example, in both the squared
and cubic specifications, there are roughly 1.5 times as many households at the peak of the
stationary distribution relative to the linear scheme.
5.2 Inequality Measures
The exact form of the dividend distribution rule has important implications for the model’s
Lorenz curve as well as its Gini coefficient, both of which are important measures of inequality
24

Figure 5: Stationary distribution
0 20 40 60 80 100
deposit/labor income
0
0.02
0.04
0.06
0.08
0.1
HANK
L10
L100
0 20 40 60 80 100
deposit/labor income
0
0.02
0.04
0.06
0.08
0.1
0.12
L10
S10
C10
Notes: This figure plots the stationary distribution generated by different models. The blue solid lines, red
dotted lines, and the yellow dashed lines on the left(right) are for the baseline HANK(L100), L10(S100), and
L100(C100) models, respectively. The x-axis is the ratio between wealth and labor income, and the y-axis
is the density.
Figure 6: Lorenz curve
0 20 40 60 80 100
population percentile
0
10
20
30
40
50
60
70
80
90
100
deposit percentile
HANK
L10
L100
45 degree line
0 20 40 60 80 100
population percentile
0
10
20
30
40
50
60
70
80
90
100
deposit percentile
L10
S10
C10
45 degree line
Notes: This figure plots the Lorenz curve of stationary wealth distribution when the dividends are distributed
according to different functions. The blue solid lines, red dotted lines, and the yellow dashed lines on the
left(right) column are for the baseline HANK(L10), L10(S10), and L100(C10) models, respectively, the thin
black solid lines are the 45 degree line. The x-axis is the fraction of population, and the y-axis is the fraction
of wealth.
on which the extant literature has often focused.
Figure 6 plots Lorenz curves for different dividend distribution schemes. A Lorenz curve
plots the cumulative fraction of overall wealth against the population percentile. In our
model, household wealth takes the form of deposits. Points along the 45-degree line represent
perfect equality; points below the 45-degree line indicate that wealth is unequally distributed,
with more wealth held by a small fraction of households.
25

Table 2: Gini coefficient
HANK L10 L100 S10 C10
Gini coeff. 0.44 0.39 0.34 0.48 0.51
Notes: This table reports the Gini coefficients in different models.
The left panel plots the Lorenz curves for linear distribution rules. The blue line corre-
sponds to our baseline specification (labeled HANK, with equal dividend distribution). The
dotted red curve and the dashed orange curve show the Lorenz curves associated with linear
distribution schemes with larger values of n (10 and 100). Consistent with the shapes of
the stationary distributions, a larger value of n reduces observed inequality and shifts the
Lorenz curves upward. In the right panel, we plot Lorenz Curves conditioning on n = 10,
but for different values of ϑ. Here we observe that larger values of ϑ shift the Lorenz curve
down, meaning there is more inequality.
Table 2 corroborates the results depicted graphically in Figure 6 by showing Gini co-
efficients for different dividend distribution rules. The Gini coefficient is the ratio of the
area between the 45-degree line and the Lorenz curve to the total area under the 45-degree
line. A larger Gini coefficient indicates higher inequality. Our baseline HANK specification
produces a Gini coefficient of 0.44. Focusing on a linear distribution scheme with higher
values of n, the model’s Gini coefficient falls. A squared or cubic specification, in contrast,
results in more observed inequality.
5.3 Macro Aggregates
Our analysis above suggests that our model is capable of generating sizable wealth inequality
with alternative dividend distribution rules. However, the question we are interested in is
not whether the model can match moments of the wealth distribution. Rather, the key
question of the paper is whether a model featuring more (or less) inequality matters for the
transmission of QE shocks into aggregate variables. We show in this subsection that there is
little economically meaningful connection between the dividend distribution rule, inequality
26
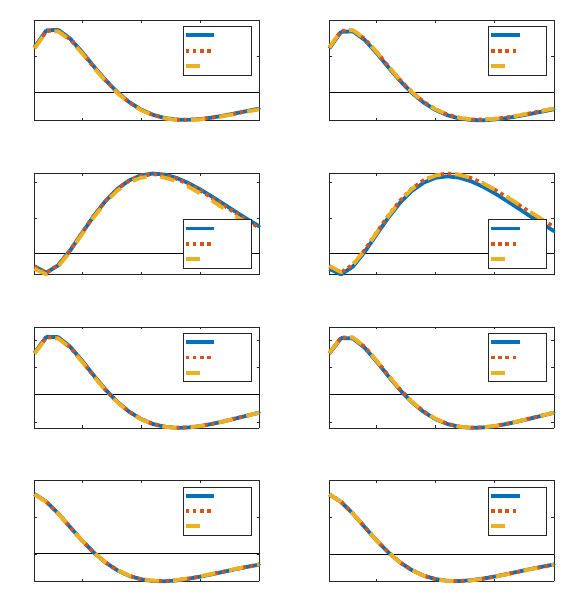
Figure 7: Impulse responses to a QE shock: HANK with different distribution
rules
5 10 15 20
0
0.5
1
output
HANK
L10
L100
5 10 15 20
0
0.1
0.2
consumption
HANK
L10
L100
5 10 15 20
-2
0
2
4
investment
HANK
L10
L100
5 10 15 20
0
0.05
0.1
inflation
HANK
L10
L100
5 10 15 20
0
0.5
1
output
L10
S10
C10
5 10 15 20
0
0.1
0.2
consumption
L10
S10
C10
5 10 15 20
-2
0
2
4
investment
L10
S10
C10
5 10 15 20
0
0.05
0.1
inflation
L10
S10
C10
Notes: This figure plots the impulse responses of aggregate variables with linear distribution under a positive
QE shock. The blue solid lines, red dotted lines, and the yellow dashed lines in the left(right) column are
for the baseline HANK(L10), L10(S10), and L100(C10) models, respectively. The x-axis is time, and y-axis
is the percentage change from steady state.
moments, and aggregate effects of QE shocks.
Figure 7 plots impulse responses to a QE shock under different dividend distribution
specifications. The picture is divided into two panels, with responses in the HANK, L10, and
L100 specifications in the left panel, and responses for the L10, S10, and C10 specifications
in the right panel. We focus only on responses of output, consumption, investment, and
inflation here, but the responses are otherwise generated in the same manner as in Figure 2.
The responses of aggregate variables to a QE shock are remarkably similar under all
specifications; this means they are all, in turn, very close to the RANK specification as well.
There are some small differences for the response of aggregate consumption, but the inflation,
output, and investment responses are almost identical across all specifications. These results
27
suggest that the exact form of the dividend distribution rule – though relevant for inequality
moments like the Gini coefficient – is unimportant for the aggregate transmission of a QE
shock. This, in turn, suggests that the literature’s heavy focus on these inequality statistics
may be misplaced, at least to the extent to which one focuses on dynamics of aggregate
variables.
6 Implications of the Macro-Distribution of Wealth
In this section, we investigate how some parameters related to the macro-distribution of
wealth impact our results. In particular, we are interested in how parameters such as the
unemployment rate, the unemployment benefit, the unemployment duration, and households’
risk aversion affect the stationary wealth distribution, and in turn the aggregate transmission
of QE shocks.
6.1 Unemployment Rate
In our baseline calibration, we set the unemployment rate to five percent. While consistent
with the data, this relatively low unemployment rate means that households face a small
probability of job loss. In this section, we allow a higher unemployment rate, which means
households face more uninsurable income risk, and study its implications for the behavior of
aggregate consumption, and hence other aggregate variables, in response to a QE shock.
Figure 8 plots the stationary wealth distribution in our model with four different targets
for the unemployment rate – our baseline specification of five percent, labeled HANK (solid
blue line), 10 percent (dotted red line), 20 percent (dashed orange line), and 40 percent
(dashed purple line). While a 40 percent unemployment rate is clearly unrealistic, it is not
unreasonable compared to labor force non-participation rates. Increasing the unemployment
rates shifts mass in the stationary distribution towards the borrowing constraint.
28
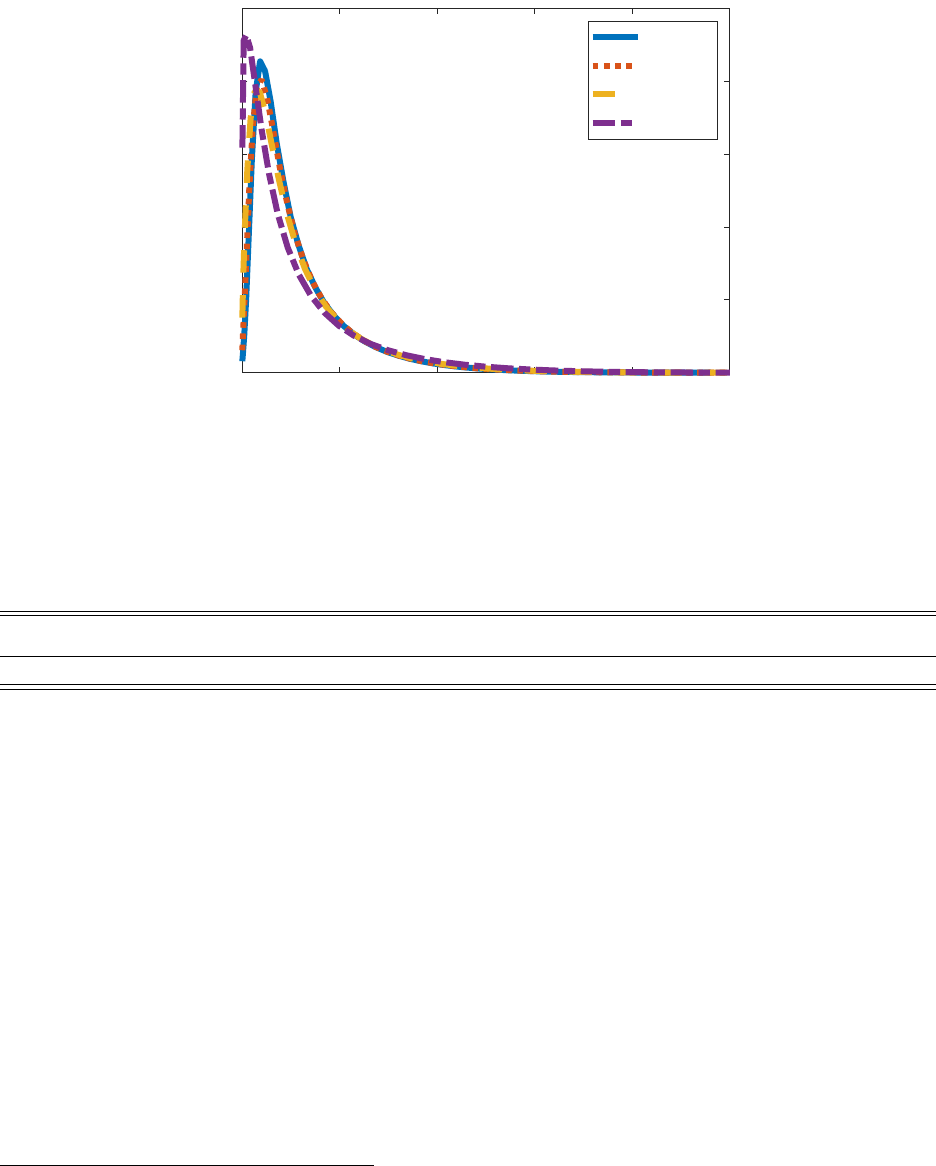
Figure 8: Stationary Distribution: HANK vs. U = 10%, 20% and 40%
0 20 40 60 80 100
deposit/labor income
0
0.02
0.04
0.06
0.08
0.1
HANK
U=10%
U=20%
U=40%
Notes: This figure plots the stationary distribution of the population. The blue solid line is for the HANK
model, the red dotted line is for the model with 10% unemployment rate, the yellow dashed line is for the
model with 20% unemployment rate, and the purple dash-dotted line is for the model with 40% unemploy-
ment rate. The x-axis is the ratio between wealth and average steady state labor income, and the y-axis is
the density.
Table 3: Households At and Near the Borrowing Constraint
HANK U = 10% U = 20% U = 40% µ = 30% µ = 50%
7.80 5.81 5.94 19.60 4.76 13.22
Notes: This table reports the percentage of households near the borrowing constraint (defined as having
deposits less than two quarters’ worth of average steady-state labor income) in different models.
Table 3 shows the percentage of households located at or near the borrowing constraint in
different specifications of our model. We define households as near the borrowing constraint
if their accumulated wealth amounts to less than two quarters’ worth of average steady-state
labor income. In our baseline HANK model, just under 8 percent of households are near
the borrowing constraint. When the unemployment rate is 40 percent, nearly 20 percent of
households have fewer than two quarters’ worth of labor income saved. It appears as though
fewer households are located near the constraint for intermediate values of unemployment
of 10 and 20 percent. This is an artifact of the way we discretize the deposit grids.
12
The
12
Since lower unemployment results in higher average labor income, fewer deposit grid points satisfy the
condition that deposits are less than two quarters’ steady-state labor income.
29
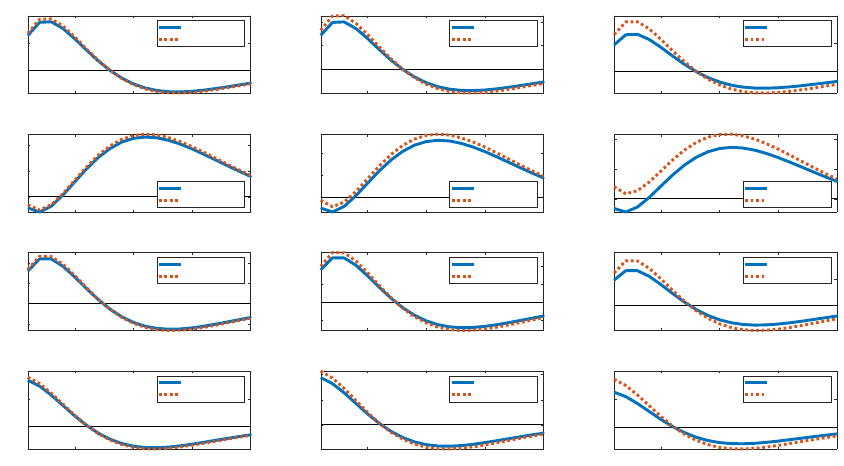
Figure 9: Impulse responses to a QE shock: HANK vs. RANK for U = 10%, 20%,
and 40%
5 10 15 20
0
0.5
1
output
RANK--U=10%
HANK--U=10%
5 10 15 20
0
0.1
0.2
consumption
RANK--U=10%
HANK--U=10%
5 10 15 20
-2
0
2
4
investment
RANK--U=10%
HANK--U=10%
5 10 15 20
0
0.05
0.1
inflation
RANK--U=10%
HANK--U=10%
5 10 15 20
-0.5
0
0.5
1
output
RANK--U=20%
HANK--U=20%
5 10 15 20
0
0.1
0.2
consumption
RANK--U=20%
HANK--U=20%
5 10 15 20
-2
0
2
4
investment
RANK--U=20%
HANK--U=20%
5 10 15 20
0
0.05
0.1
inflation
RANK--U=20%
HANK--U=20%
5 10 15 20
0
1
2
output
RANK--U=40%
HANK--U=40%
5 10 15 20
0
0.2
0.4
consumption
RANK--U=40%
HANK--U=40%
5 10 15 20
0
5
10
investment
RANK--U=40%
HANK--U=40%
5 10 15 20
0
0.1
0.2
inflation
RANK--U=40%
HANK--U=40%
Notes: This figure plots the impulse responses of aggregate variables under a 4% QE shock. The blue
solid lines and red dotted lines on the left/middle/right column are for the HANK and RANK models with
10%/20%/40% unemployment rate, respectively. The x-axis is time, and the y-axis is the percentage change
from steady state.
extreme value of 40 percent unemployment gives a clearer sense of how the wealth distribution
varies with the unemployment rate. Note further, these numbers tend to underestimate
the true fraction of households that are located near the borrowing constraint because poor
people tend to work more and hence have a higher steady-state income than richer households
via a wealth channel, but we are defining being near the borrowing constraint based on
average labor income, not the income of individual households. This makes the denominator
smaller and the overall wealth/income larger.
Figure 9 plots impulse response to a QE shock in these scenarios. The left/middle/right
panel considers an unemployment target of 10/20/40 percent. Solid blue lines refer to re-
sponses in a RANK version of our model, calibrated to have a comparable steady state labor
input as the corresponding HANK model. Dotted red lines are impulse responses in a HANK
model. Compared to a RANK model, aggregate variables react more the higher is the unem-
ployment rate. These differences are small and mostly not visible for a 10 percent and even
30
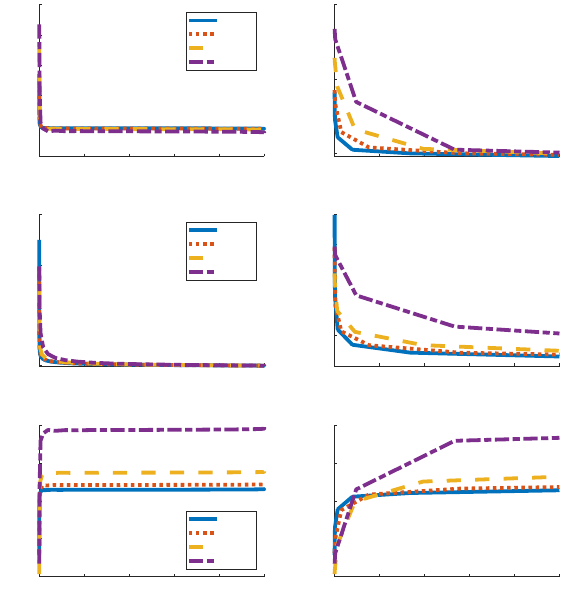
Figure 10: First period individual responses to a QE shock: HANK vs. U = 10%,
20%, and 40%
0 20 40 60 80 100
-0.5
0
0.5
1
1.5
2
consumption
HANK
U=10%
U=20%
U=40%
0 20 40 60 80 100
0
20
40
60
deposit
HANK
U=10%
U=20%
U=40%
0 20 40 60 80 100
deposit percentile
-0.5
0
0.5
1
1.5
labor
HANK
U=10%
U=20%
U=40%
0 0.2 0.4 0.6 0.8 1
0
0.5
1
1.5
2
consumption
0 0.2 0.4 0.6 0.8 1
0
10
20
30
40
50
deposit
0 0.2 0.4 0.6 0.8 1
deposit percentile
-0.5
0
0.5
1
1.5
labor
Notes: This figure plots the impulse responses of (employed) individual decision variables (consumption,
deposits, and labor supply) in the period when a 4% positive QE shock hits. The blue solid lines, red dotted
lines, yellow dashed lines, and purple dash-dotted lines are for the baseline HANK model and the models
with U = 10%, U = 20%, and U = 40%, respectively. The x-axis is the wealth fraction from poor to rich,
and the y-axis is the percentage change from steady state. The left panel plots first-period responses across
the full wealth distribution, while the right panel zooms in on the bottom one percent.
a 20 percent unemployment target. There are somewhat more meaningful differences when
we target unemployment of 40 percent. Consumption rises, rather than falls, with output
and investment reacting about 20 percent more on impact to an expansionary QE shock
compared to a RANK model. Still, the responses with this extreme value of unemployment
are nevertheless qualitatively similar to the RANK specification as well as to our benchmark
HANK model.
To provide some intuition, Figure 10 plots the first-period individual choice variable
responses to a QE shock as a function of wealth. The figure is analogous to Figure 3, but
compares HANK responses with different unemployment rates. The main differences are for
31

Figure 11: Stationary Distribution: HANK vs µ = 30% and 50%
0 20 40 60 80 100
deposit/labor income
0
0.02
0.04
0.06
0.08
0.1
HANK
=30%
=50%
Notes: This figure plots the stationary distribution of the population. The blue solid lines are for the HANK
model, the red dotted lines are for the model with 30% unemployment benefits, and the yellow dashed lines
are for the model with 50% unemployment benefits. The x-axis is the ratio between wealth and labor income,
and the y-axis is the density.
the poorest households, who increase their consumption and savings, and decrease labor,
by more the higher is the unemployment rate. It remains the case that households located
further from the borrowing constraint behave similarly with respect to consumption and
saving choices across different specifications, and in turn, similarly to the representative
agent counterpart from a RANK specification.
6.2 Unemployment Benefit
We next consider the role played by the unemployment benefit, µ in our model. We consider
both a smaller (µ = 0.30) and larger (µ = 0.50) value of this parameter compared to our
benchmark specification (µ = 0.40). Figure 11 plots the stationary distributions of wealth
for these three different values of the unemployment benefit. The bigger is µ, the more
mass is concentrated in the left tail near the borrowing constraint. The reason for this is
straightforward – with a bigger unemployment benefit, the cost of unemployment is smaller,
and households consequently have less incentive to self-insure against unemployment by
32
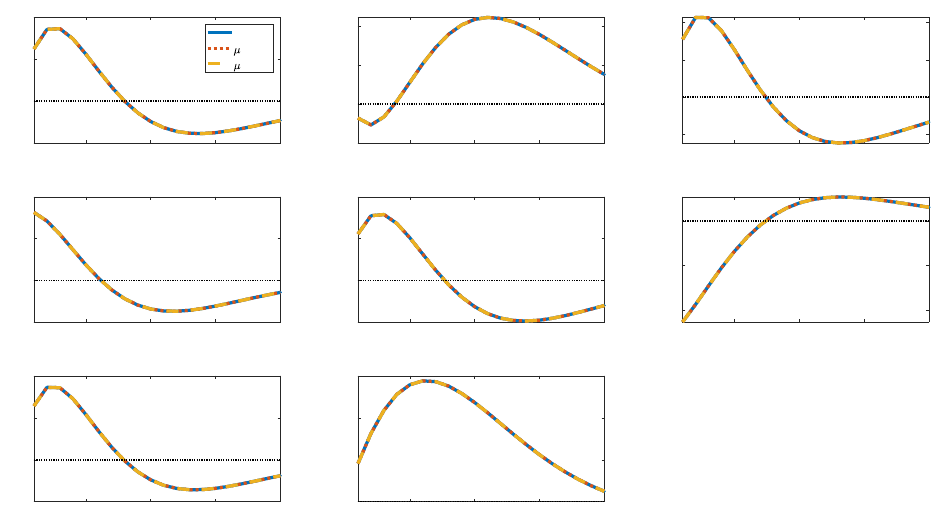
Figure 12: Impulse responses to a QE shock: HANK vs. µ = 30% and 50%
5 10 15 20
-0.5
0
0.5
1
output
HANK
=30%
=50%
5 10 15 20
-0.1
0
0.1
0.2
consumption
5 10 15 20
-2
0
2
4
investment
5 10 15 20
-0.05
0
0.05
0.1
inflation
5 10 15 20
-0.05
0
0.05
0.1
policy rate
5 10 15 20
-0.2
-0.1
0
corp. bond spread
5 10 15 20
-0.5
0
0.5
1
labor
5 10 15 20
0
0.5
1
1.5
deposit
Notes: This figure plots the impulse responses of aggregate variables under a 4% QE shock. The blue solid
lines are for the HANK model, the red dotted lines are for the model with 30% unemployment benefits, and
the yellow dashed lines are for the model with 50% unemployment benefits. X-axis is time in quarters, and
Y-axis is the percentage change from steady state.
saving. We see this channel at play in the right columns of Table 3, which show that with a
higher value of µ, a larger percentage of households are located near the borrowing constraint.
Figure 12 plots the impulse responses of aggregate variables to a QE shock with these
different values of the unemployment benefit. The responses with µ = 0.30 or µ = 0.50 are
virtually identical to the responses in our benchmark HANK specification.
6.3 Unemployment Duration
The duration of unemployment spells, governed in our model by the parameter p, is another
parameter of interest. In our benchmark model, we set this parameter to p = 1/2, implying
an average duration of unemployment spells of two quarters. We consider now a value of
p = 9/10, which implies a typical duration of unemployment of 10 quarters. The model is
re-parameterized with this new value of p to still target our benchmark unemployment rate
33
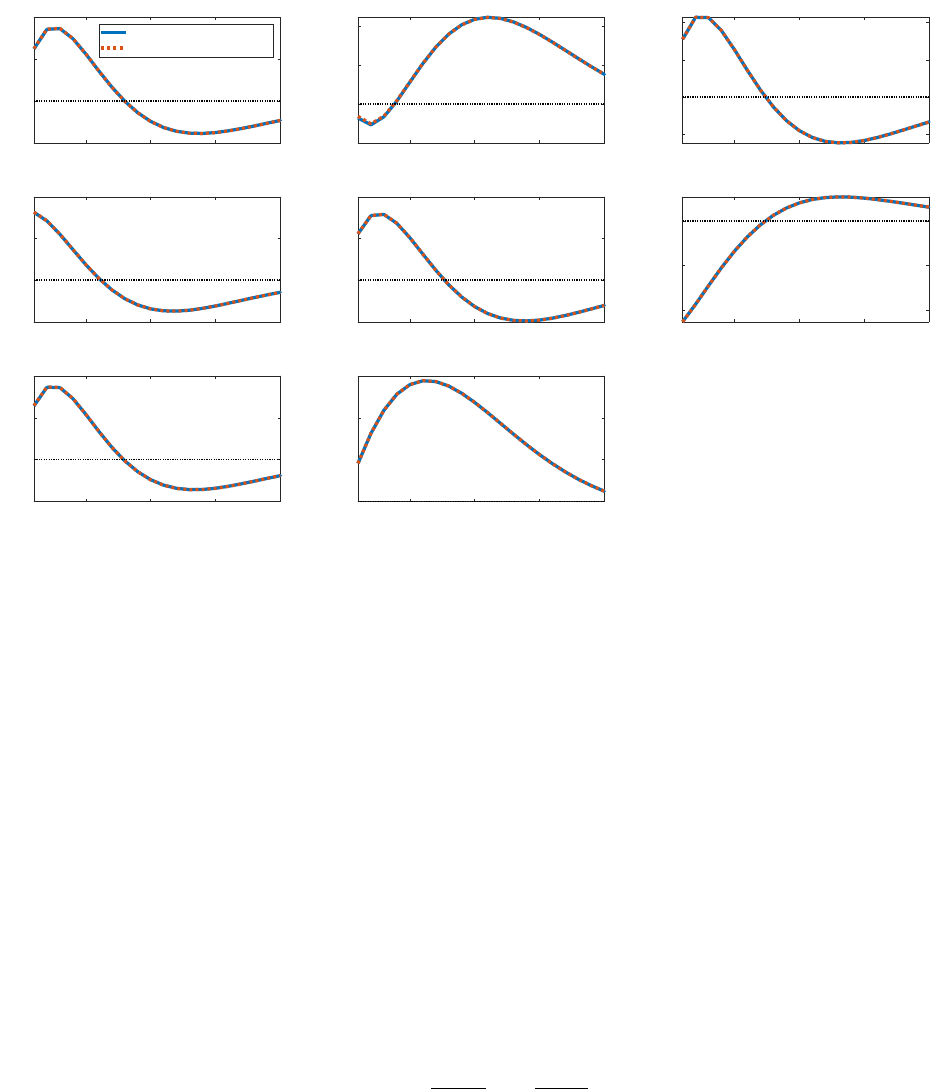
Figure 13: Impulse responses to a QE shock: unemployment duration = 2 vs. 10
quarters
5 10 15 20
-0.5
0
0.5
1
output
Unemployment duration=2
Unemployment duration=10
5 10 15 20
-0.1
0
0.1
0.2
consumption
5 10 15 20
-2
0
2
4
investment
5 10 15 20
-0.05
0
0.05
0.1
inflation
5 10 15 20
-0.05
0
0.05
0.1
policy rate
5 10 15 20
-0.2
-0.1
0
corp. bond spread
5 10 15 20
-0.5
0
0.5
1
labor
5 10 15 20
0
0.5
1
1.5
deposit
Notes: This figure plots the impulse responses of aggregate variables under a 4% QE shock. The blue solid
lines are for the RANK model, and the red dashed lines are for the HANK model. X-axis is time in quarters,
and Y-axis is the percentage change from steady state.
of five percent. Figure 13 plots aggregate responses to a QE shock for both our baseline
HANK specification as well as this new specification with a lower value of p. The aggregate
impulse responses are virtually identical.
6.4 Risk Aversion
Finally, we investigate the role played by households’ degree of risk aversion. Instead of
assuming log utility over consumption as in (2.1), we allow for a more general isoelastic
utility function, with lifetime flow utility now given by:
E
0
∞
X
t=0
β
t
c
1−σ
i,t
1 − σ
− χ
l
1+η
j,t
1 + η
!
,
where σ measures the coefficient of relative risk aversion. Log utility is a special case with
σ = 1.
34
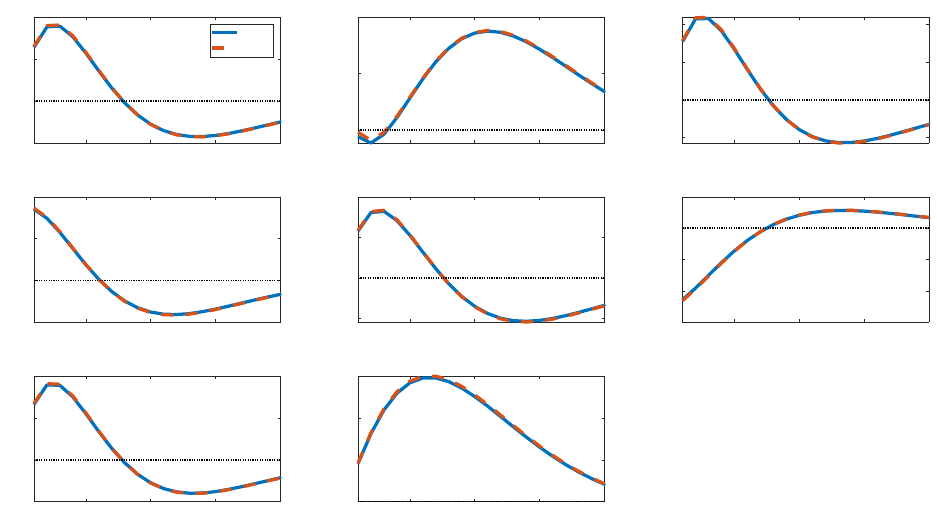
Figure 14: Impulse responses to a QE shock: RANK vs. HANK for CRRA utility
5 10 15 20
-0.5
0
0.5
1
output
RANK
HANK
5 10 15 20
0
0.05
0.1
consumption
5 10 15 20
-2
0
2
4
investment
5 10 15 20
-0.05
0
0.05
0.1
inflation
5 10 15 20
-0.05
0
0.05
0.1
policy rate
5 10 15 20
-0.3
-0.2
-0.1
0
0.1
corp. bond spread
5 10 15 20
-0.5
0
0.5
1
labor
5 10 15 20
0
0.5
1
1.5
deposit
Notes: This figure plots the impulse responses of aggregate variables under a 4% QE shock. The blue solid
lines are for the RANK model, and the red dashed lines are for the HANK model. X-axis is time in quarters,
and Y-axis is the percentage change from steady state.
We consider a higher value of σ = 3, implying substantially more risk aversion than in
the case of log utility. Figure 14 plots impulse responses for a RANK version of our model
with σ = 3 (solid blue) and the HANK version with the same risk aversion (dashed red).
There is practically no difference between the two specifications.
7 Conclusion
We developed a quantitative DSGE model to study the aggregate implications of central bank
asset purchases when there is substantial household wealth heterogeneity. The financial
and production sides of the model are similar to Sims and Wu (2021a), which features
constrained financial intermediaries and scope for QE to matter. We model households
similarly to Krusell and Smith (1998): they are heterogeneous with respect to wealth, face
uninsurable unemployment risk, and are subject to a borrowing constraint. Different from
35
them, households endogenously choose labor supply. We developed a solution method that
is compatible with Dynare and uses perturbation methods to solve and simulate the model.
We find that the aggregate responses to central bank asset purchases are very similar in
a HANK specification compared to a RANK version of the model. We consider alternative
assumptions about the micro- and macro-distributions of wealth. For the former, we vary
how dividends are distributed across households. While different dividend distribution rules
can generate different amounts of wealth inequality based on popular metrics, they have
little discernible impact on how aggregate variables like output react to a QE shock. For the
latter, we examine how the unemployment rate, the unemployment benefit, the duration of
unemployment, and the degree of relative risk aversion impact the aggregate transmission of
QE shocks. For reasonable values of macro parameters, we find no discernible differences in
the impact of QE shocks between HANK and RANK models. We conclude that a RANK
specification may provide an adequate approximation for understanding the aggregate im-
plications of QE.
36

References
Acharya, Sushant and Keshav Dogra, “Understanding HANK: Insights From a
PRANK,” Econometrica, 2020, 88 (3), 1113–1158.
Algan, Yann, Olivier Allais, and Wouter J. Den Haan, “Solving heterogeneous-agent
models with parameterized cross-sectional distributions,” Journal of Economic Dynamics
and Control, 2008, 32 (3), 875 – 908.
Alves, Felipe, Greg Kaplan, Benjamin Moll, and Giovanni Violante, “A Further
Look at the Propagation of Monetary Policy Shocks in HANK,” Journal of Money, Credit
and Banking, 2020, 52 (S2), 521–559.
Auclert, Adrien, “Monetary Policy and the Redistribution Channel,” American Economic
Review, June 2019, 109 (6), 2333–67.
Cui, Wei and Vincent Sterk, “Quantitative easing with heterogeneous agents,” Journal
of Monetary Economics, October 2021, 123, 68–90.
Debortoli, Davide and Jordi Gali, “Idiosyncratic Income Risk and Aggregate Fluctua-
tions,” 2022. NBER Working Paper 29704.
Gertler, Mark and Peter Karadi, “A Model of Unconventional Monetary Policy,” Jour-
nal of Monetary Economics, 2011, pp. 17–34.
and , “QE 1 vs. 2 vs. 3...: A Framework for Analyzing Large-Scale Asset Purchases as
a Monetary Policy Tool,” International Journal of Central Banking, 2013, 9(S1), 5–53.
Judd, Kenneth L., Numerical Methods in Economics, Vol. 1 of MIT Press Books, The
MIT Press, December 1998.
Kaplan, Greg, Benjamin Moll, and Giovanni L. Violante, “Monetary Policy Accord-
ing to HANK,” American Economic Review, March 2018, 108 (3), 697–743.
37
Krusell, Per and Anthony A. Smith Jr., “Income and wealth heterogeneity in the
macroeconomy,” Journal of Political Economy, 1998, 106 (5), 867–896.
McKay, Alisdair, Emi Nakamura, and J´on Steinsson, “The Power of Forward Guid-
ance Revisited,” American Economic Review, October 2016, 106 (10), 3133–58.
Ravn, Morten O and Vincent Sterk, “Macroeconomic Fluctuations with HANK &
SAM: an Analytical Approach,” Journal of the European Economic Association, 06 2020,
19 (2), 1162–1202.
Reiter, Michael, “Solving heterogeneous-agent models by projection and perturbation,”
Journal of Economic Dynamics and Control, 2009, 33, 649–665.
Shimer, Robert, “The Cyclical Behavior of Equilibrium Unemployment and Vacancies,”
American Economic Review, March 2005, 95 (1), 25–49.
Sims, Eric and Jing Cynthia Wu, “Are QE and Conventional Monetary Policy Substi-
tutable?,” International Journal of Central Banking, 2020, 16 (1), 195–230.
and , “Evaluating Central Banks’ Tool Kit: Past, Present, and Future,” Journal of
Monetary Economics, 2021, 185, 135–160.
and , “Wall Street QE vs. Main Street Lending,” 2021. NBER Working Paper No.
27295.
, , and Ji Zhang, “The Four Equation New Keynesian Model,” Review of Economics
and Statistics, forthcoming.
Taylor, John B., “Discretion versus Policy Rules in Practice,” Carnegie-Rochester Con-
ference Series on Public Policy, 1993, 39, 195–214.
Winberry, Thomas, “A method for solving and estimating heterogeneous agent macro
models,” Quantitative Economics, 2018, 9 (3), 1123–1151.
38
Woodford, Michael, “Fiscal requirements for price stability,” JMCB, August 2001, 33 (3),
669–728.
Young, Eric R., “Solving the incomplete markets model with aggregate uncertainty us-
ing the Krusell–Smith algorithm and non-stochastic simulations,” Journal of Economic
Dynamics and Control, 2010, 34 (1), 36 – 41.
39
A Model Details
This appendix contains details from the model discussed in Section 2.
A.1 Labor Market
Labor unions, indexed by h ∈ [0, 1] purchase labor from households at price M RS
t
, repackage it into L
d,t
(h),
and sell it to a representative labor contractor. A representative labor contractor combines differentiated
labor into final labor used in production, via CES technology with elasticity ε
w
. The demand curve each
labor union faces is
L
d,t
(h) =
W
t
(h)
W
t
−ε
w
L
d,t
(A.1)
W
t
(h) is the wage paid for union h’s labor and W
t
is the aggregate wage, which satisfies
W
1−ϵ
w
t
=
Z
1
0
W
t
(h)
1−ϵ
w
dh (A.2)
Labor unions are subject to a Calvo-type nominal rigidity. Each period, a union may re-optimize its
wage with probability 1 − ϕ
w
with ϕ
w
∈ [0, 1]. Non-reoptimized wages are indexed to lagged inflation at
γ
w
∈ [0, 1]. A labor union chooses a wage to maximize the present discounted value of real profits:
max
W
t
(h)
E
t
∞
X
j=0
ϕ
j
w
Λ
t,t+j
"
P
t+j−1
P
t−1
(1−ϵ
w
)γ
w
W
t
(h)
1−ϵ
w
P
ϵ
t−1
t+j
w
ϵ
w
t+j
L
d,t+j
−
mrs
t+j
P
t+j−1
P
t−1
−ϵ
w
γ
w
W
t
(h)
−ϵ
w
P
ϵ
w
t+j
w
ϵ
w
t+j
L
d,t+j
#
(A.3)
where Λ
t,t+j
= Λ
t,t+1
· · · Λ
t+j−1,t+j
.
The first order condition is
(ϵ
w
− 1)W
t
(h)
−ϵ
w
E
t
∞
X
j=0
ϕ
j
w
Λ
t,t+j
P
t+j−1
P
t−1
(1−ϵ
w
)γ
w
P
ϵ
w
−1
t+j
w
ϵ
w
t+j
L
d,t+j
=
ϵ
w
W
t
(h)
−ϵ
w
−1
E
t
∞
X
j=0
ϕ
j
w
Λ
t,t+j
mrs
t+j
P
t+j−1
P
t−1
−ϵ
w
γ
w
P
ϵ
w
t+j
w
ϵ
w
t+j
L
d,t+j
The reset wage is the same across all labor unions. Hence, drop the h index, and the optimal price W
∗
t
can
be written as:
W
∗
t
=
ϵ
w
ϵ
w
− 1
F
1,t
F
2,t
where F
1,t
and F
2,t
are recursive representations of the infinite sums above:
F
1,t
= mrs
t
P
ϵ
w
t
w
ϵ
w
t
L
d,t
+ ϕ
w
Λ
t,t+1
Π
−ϵ
w
γ
w
t
F
1,t+1
F
2,t
= P
ϵ
w
−1
t
w
ϵ
w
t
L
d,t
+ ϕ
w
Λ
t,t+1
Π
(1−ϵ
w
)γ
w
t
F
2,t+1
Written in real terms, w
∗
t
= W
∗
t
/P
t
, it satisfies:
40

w
∗
t
=
ϵ
w
ϵ
w
− 1
f
1,t
f
2,t
(A.4)
f
1,t
= mrs
t
w
ϵ
w
t
L
d,t
+ ϕ
w
E
t
Λ
t,t+1
Π
t+1
Π
γ
w
t
ϵ
w
f
1,t+1
(A.5)
f
2,t
= w
ϵ
w
t
L
d,t
+ ϕ
w
E
t
Λ
t,t+1
Π
t+1
Π
γ
w
t
ϵ
w
−1
f
2,t+1
(A.6)
where w
t
= W
t
/P
t
is the aggregate real wage from (A.2), and f
1,t
= F
1,t
/P
ϵ
w
t
and f
2,t
= F
2,t
/P
ϵ
w
−1
t
.
Aggregation Integrate (A.1) across h, noting that
R
1
0
L
d,t
(h)dh = L
t
. Using the demand function for
a union’s labor, (A.1), yields
L
t
= L
d,t
v
w
t
(A.7)
where v
w
t
is a measure of wage dispersion:
v
w
t
=
Z
1
0
w
t
(h)
w
t
−ϵ
w
dh
Note that this can be written in terms of real wages since it is a ratio. Because of properties of Calvo
wage-setting, we can write this as
v
w
t
= (1 − ϕ
w
)
w
∗
t
w
t
−ϵ
w
+
Z
1
1−ϕ
w
Π
γ
w
t−1
W
t−1
(h)
W
t
−ϵ
w
dh
= (1 − ϕ
w
)
w
∗
t
w
t
−ϵ
w
+ Π
−γ
w
ϵ
w
t−1
W
ϵ
w
t
W
−ϵ
w
t−1
Z
1
1−ϕ
w
W
t−1
(h)
W
t−1
−ϵ
w
dh
which may be written as
v
w
t
= (1 − ϕ
w
)
w
∗
t
w
t
−ϵ
w
+ ϕ
w
Π
−γ
w
ϵ
w
t−1
W
ϵ
w
t
W
−ϵ
w
t−1
v
w
t−1
Expressing this in real terms gives
v
w
t
= (1 − ϕ
w
)
w
∗
t
w
t
−ϵ
w
+ ϕ
w
Π
t
Π
γ
w
t−1
ϵ
w
w
t
w
t−1
ϵ
w
v
w
t−1
(A.8)
From (A.2), we have
W
1−ϵ
w
t
= (1 − ϕ
w
) (W
∗
t
)
1−ϵ
w
+
Z
1
1−ϕ
w
Π
γ
w
t−1
W
t−1
(h)
1−ϵ
w
dh
Via a law of large numbers, this is
W
1−ϵ
w
t
= (1 − ϕ
w
) (W
∗
t
)
1−ϵ
w
+ Π
γ
w
(1−ϵ
w
)
t−1
ϕ
w
W
1−ϵ
w
t−1
Dividing both sides by P
1−ϵ
w
t
gives
w
1−ϵ
w
t
= (1 − ϕ
w
) (w
∗
t
)
1−ϵ
w
+ ϕ
w
Π
γ
w
(1−ϵ
w
)
t−1
Π
ϵ
w
−1
t
w
1−ϵ
w
t−1
(A.9)
41
A.2 Capital Producers
A representative capital producer transfers raw investment goods I
t
into new capital
ˆ
I
t
via:
ˆ
I
t
=
1 − S
I
t
I
t−1
I
t
(A.10)
where S (I
t
/I
t−1
) =
κ
I
2
(I
t
/I
t−1
− 1)
2
is the investment adjustment cost.
The capital producer sells new capital to wholesale firms, and earns real profit in period t:
div
k,t
= p
k
t
1 − S
I
t
I
t−1
I
t
− I
t
(A.11)
where p
k
t
is the real price of new capital. The object of a capital producer is to maximize the present value
of profit:
max
I
t
E
t
∞
X
j=0
Λ
t,t+j
p
k
t
1 − S
I
t+j
I
t+j−1
I
t+j
− I
t+j
The first order condition is
1 = p
k
t
1 − S
I
t
I
t−1
− S
′
I
t
I
t−1
I
t
I
t−1
+ E
t
Λ
t,t+1
p
k
t+1
S
′
I
t+1
I
t
I
t+1
I
t
2
(A.12)
A.3 Output
The final output good, Y
t
, is a CES aggregate of retail outputs with elasticity of substitution ϵ
p
> 1. Profit
maximization by the final good producer generates a demand curve for each retail output and an expression
for the aggregate price index:
Y
t
(f) =
P
t
(f)
P
t
−ϵ
p
Y
t
. (A.13)
The price of the final goods, P
t
, satisfies:
P
1−ϵ
p
t
=
Z
1
0
P
t
(f)
1−ϵ
p
df. (A.14)
Each period, a retailer faces a constant probability, 1 − ϕ
p
, of being able to adjust its price. Consider
the problem of a retailer given the opportunity to adjust in period t. When it sets a price, it must take into
account that the price chosen in t will still be in effect in period t + j with probability ϕ
j
p
. Indexation to
lagged inflation means that an unupdated price in period t + j will be: P
t
(f)
P
t+j−1
P
t−1
γ
p
. When choosing a
price, the retailer maximizes the present discounted value of real profits returned to the household, where
discounting is by the household’s stochastic discount factor augmented by the probability of non-adjustment:
max
P
t
(f)
E
t
∞
X
j=0
ϕ
j
p
Λ
t,t+j
"
P
t
(f)
1−ϵ
p
P
t+j−1
P
t−1
(1−ϵ
p
)γ
p
P
ϵ
p
−1
t+j
Y
t+j
− P
m,t+j
P
t
(f)
−ϵ
p
P
t+j−1
P
t−1
−ϵ
p
γ
p
P
ϵ
p
−1
t+j
Y
t+j
#
42
The first order condition is
(ϵ
p
− 1)P
t
(f)
−ϵ
p
E
t
∞
X
j=0
ϕ
j
p
Λ
t,t+j
P
t+j−1
P
t−1
(1−ϵ
p
)γ
p
P
ϵ
p
−1
t+j
Y
t+j
=
ϵ
p
P
t
(f)
−ϵ
p
−1
E
t
∞
X
j=0
ϕ
j
p
Λ
t,t+j
P
m,t+j
P
t+j−1
P
t−1
−ϵ
p
γ
p
P
ϵ
p
t+j
Y
t+j
Define variables:
X
1,t
=
∞
X
j=0
(ϕ
p
β)
j
µ
t+j
µ
t
P
m,t+j
P
t+j−1
P
t−1
−ϵ
p
γ
p
P
ϵ
p
t+j
Y
t+j
X
2,t
=
∞
X
j=0
(ϕ
p
β)
j
µ
t+j
µ
t
P
t+j−1
P
t−1
(1−ϵ
p
)γ
p
P
ϵ
p
−1
t+j
Y
t+j
These can be written recursively as:
X
1,t
= p
m,t
P
ϵ
p
t
Y
t
+ ϕ
p
Λ
t,t+1
Π
−ϵ
p
γ
p
t
X
1,t+1
X
2,t
= P
ϵ
p
−1
t
Y
t
+ ϕ
p
Λ
t,t+1
Π
(1−ϵ
p
)γ
p
t
X
2,t+1
Note, all retailers set the same price. We call this reset price P
∗
t
. Hence, the first order condition can be
written as
P
∗
t
=
ϵ
p
ϵ
p
− 1
X
1,t
X
2,t
Defining x
1,t
= X
1,t
/P
ϵ
p
t
, x
2,t
= X
2,t
/P
ϵ
p
−1
t
, and p
∗
t
= P
∗
t
/P
t
gives
p
∗
t
=
ϵ
p
ϵ
p
− 1
x
1,t
x
2,t
(A.15)
x
1,t
= p
m,t
Y
t
+ ϕ
p
E
t
Λ
t,t+1
Π
t+1
Π
γ
p
t
ϵ
p
x
1,t+1
(A.16)
x
2,t
= Y
t
+ ϕ
p
E
t
Λ
t,t+1
Π
t+1
Π
γ
p
t
ϵ
p
−1
x
2,t+1
(A.17)
where p
m,t
=
P
m,t
P
t
.
Aggregation Integrate the demand for retail output, (A.13), across retailers, noting that Y
t
(f) =
Y
m,t
(f),
R
1
0
Y
m,t
(f)df = Y
m,t
, where Y
m,t
is wholesale output. This yields
Y
t
v
p
t
= Y
m,t
(A.18)
where
v
p
t
=
Z
1
0
P
t
(f)
P
t
−ϵ
p
df
This is a measure of price dispersion. Using properties of Calvo pricing with indexation to lagged inflation
yields:
v
p
t
= (1 − ϕ
p
) (p
∗
t
)
−ϵ
p
+
Z
1
1−ϕ
p
Π
γ
p
t−1
P
t−1
(f)
P
t
!
−ϵ
p
df
= (1 − ϕ
p
) (p
∗
t
)
−ϵ
p
+ Π
−γ
p
ϵ
p
t−1
P
ϵ
p
t
P
−ϵ
p
t−1
Z
1
1−ϕ
p
P
t−1
(f)
P
t−1
−ϵ
p
df
43

Via a law of large numbers, this reduces to
v
p
t
= (1 − ϕ
p
) (p
∗
t
)
−ϵ
p
+ ϕ
p
Π
t
Π
γ
p
t−1
!
ϵ
p
v
p
t−1
(A.19)
Similarly, the aggregate price index, (A.14), may be written as:
P
1−ϵ
p
t
= (1 − ϕ
p
) (P
∗
t
)
1−ϵ
p
+
Z
1
1−ϕ
p
Π
γ
p
(1−ϵ
p
)
t−1
P
t−1
(f)
1−ϵ
p
df
= (1 − ϕ
p
) (P
∗
t
)
1−ϵ
p
+ ϕ
p
Π
γ
p
(1−ϵ
p
)
t−1
P
1−ϵ
p
t−1
Divide both sides by P
1−ϵ
p
t
to obtain
1 = (1 − ϕ
p
) (p
∗
t
)
1−ϵ
p
+ ϕ
p
Π
γ
p
(1−ϵ
p
)
t−1
Π
ϵ
p
−1
t
(A.20)
The representative wholesale firm produces output according to a Cobb-Douglas technology:
Y
m,t
= A
t
(u
t
K
t
)
α
L
1−α
d,t
(A.21)
Y
m,t
is flow output, u
t
is the capital utilization rate, and L
d,t
is labor input. 0 < α < 1 is the exponent on
capital services in the production function. A
t
is an exogenous productivity variable that obeys an exogenous
stochastic process. K
t
is the stock of physical capital, which the firm owns. Physical capital accumulates
according to a standard law of motion:
K
t+1
=
ˆ
I
t
+ (1 − δ(u
t
))K
t
(A.22)
where δ (u
t
) = δ
0
+δ
1
(u
t
− 1)+
δ
2
2
(u
t
− 1)
2
is the capital depreciation rate and depends on capital utilization.
The wholesale firm must issue perpetual bonds to finance the purchase of new physical capital,
ˆ
I
t
.
Different than them, we only require the firm to finance a constant fraction, ψ ∈ [0, 1], of investment, not
the entirety. This gives rise to a “loan in advance constraint” of the form:
ψP
k
t
I
t
≤ Q
t
CF
m,t
= Q
t
(F
m,t
− κF
m,t−1
) , (A.23)
where P
k
t
is the price at which the wholesale firm purchases new physical capital.
The wholesale firm hires labor in a competitive spot market at nominal wage W
t
. Its nominal dividend
is
DIV
m,t
= P
m,t
A
t
K
α
t
L
1−α
d,t
− W
t
L
d,t
− P
k
t
I
t
− F
m,t−1
+ Q
t
(F
m,t
− κF
m,t−1
) (A.24)
The firm maximizes the present discounted value of real dividends, where discounting is by the stochastic
discount factor of households. The first order conditions are
w
t
= (1 − α)p
m,t
A
t
K
α
t
L
−α
d,t
(A.25)
p
k
t
M
1,t
δ
′
(u
t
) = αp
m,t
(u
t
K
t
)
α−1
L
1−α
d,t
(A.26)
p
k
t
M
1,t
= E
t
Λ
t,t+1
h
αp
m,t+1
A
t+1
K
α−1
t+1
L
1−α
d,t+1
+ (1 − δ(u
t
))p
k
t+1
M
1,t+1
i
(A.27)
Q
t
M
2,t
= E
t
Λ
t,t+1
Π
−1
t+1
[1 + κQ
t+1
M
2,t+1
] (A.28)
M
1,t
− 1
M
2,t
− 1
= ψ (A.29)
w
t
= W
t
/P
t
is the real wage, p
m,t
= P
m,t
/P
t
is the relative price of wholesale output, and p
k
t
= P
k
t
/P
t
is the
relative price of new capital. (A.25) is the standard static first order condition for labor demand. M
1,t
is one
plus the product of ψ with the multiplier on the constraint that firms must issue bonds to finance investment,
(A.23), while M
2,t
is simply one plus the multiplier on the constraint. (A.26) is the first-order condition for
capital utilization. (A.27) and (A.28) are optimality conditions for capital and bonds, respectively. If the
44

constraint did not bind, then M
1,t
= M
2,t
= 1 and (A.27) - (A.28) would reduce to standard asset pricing
conditions. M
1,t
serves as an endogenous “investment wedge” and M
2,t
can be thought of as a “financial
wedge.” These wedges distort the standard asset pricing decisions and fluctuations in these wedges are the
mechanism through which QE type policies transmit to the real economy.
A.4 Exogenous Processes and Aggregation
Aggregate productivity, A
t
, and government spending, G
t
follow AR(1) processes in the log:
ln A
t
= ρ
A
ln A
t−1
+ s
A
ϵ
A,t
, (A.30)
ln G
t
= (1 − ρ
G
) ln G + ρ
G
ln G
t−1
+ s
G
ϵ
G,t
. (A.31)
Autoregressive parameters are restricted to lie between zero and one, and shocks are drawn from standard
normal distributions, with s
A
, and s
G
denoting standard deviations. G is the non-stochastic steady state
value of government spending. The non-stochastic steady state value of labor productivity is normalized to
unity.
The exogenous process for central bank holdings of private bonds is given in (2.28). There is a similar
law of motion for central bank holdings of government bonds:
ln b
cb,t
= (1 − ρ
b
)b
cb
+ ρ
b
ln b
cb,t−1
+ σ
b
ϵ
b,t
. (A.32)
There are therefore five exogenous shocks in the model: productivity (ϵ
A,t
), government spending (ϵ
G,t
),
monetary policy (ϵ
r,t
), private QE (ϵ
f,t
), and public QE (ϵ
b,t
).
Privately-issued and government-issued bonds must be held by either financial intermediaries or the
central bank. In real terms, the bond market-clearing conditions are:
f
m,t
= f
t
+ f
cb,t
(A.33)
¯
b
G
= b
t
+ b
cb,t
, (A.34)
where f
t
=
P
i
f
i,t
and b
t
=
P
i
b
i,t
.
Aggregated across intermediaries, and written in real terms, the aggregate financial intermediary balance
sheet condition is:
Q
t
f
t
+ Q
B,t
b
t
+ re
t
= d
t
+ n
t
. (A.35)
The aggregate dynamics of intermediary net worth are given by:
n
t
= σΠ
−1
t
h
(R
F
t
− R
d
t−1
)Q
t−1
f
t−1
+ (R
B
t
− R
d
t−1
)Q
B,t−1
b
t−1
+ (R
re
t−1
− R
d
t−1
)re
t−1
+ R
d
t−1
n
t−1
i
+ X (A.36)
Similarly, aggregating the endogenous leverage constraint across intermediaries yields:
Q
t
f
t
+ ∆Q
B,t
b
t
≤ ϕ
t
n
t
(A.37)
The total dividends from the retail firms, wholesale firm, capital producer, labor union, and financial
intermediaries amount to
div
t
= Y
t
− mrs
t
L
t
− I
t
+ Q
t
f
m,t
− κ
f
m,t−1
Π
t
−
f
m,t−1
Π
t
+
1 − σ
σ
(n
t
− X). (A.38)
The aggregate resource constraint is standard:
Y
t
= C
t
+ I
t
+ G
t
(A.39)
45

B Approximating Individual Policy Functions
For the Chebyshev polynomials in (3.1), ξ(d) = 2
d−d
¯
d−d
− 1 transforms the interval d ∈ (d,
¯
d) to (−1, 1), and
the Chebyshev polynomials are defined as following:
T
n
(x) = cos(n arccos x) (B.1)
The algorithm aims to fit a set of nodes {d
m
}
M
m=1
with an N order polynomial, where M = N + 1. The
Chebyshev nodes defined on (−1, 1) are
x
m
= − cos
2m − 1
2M
π
. (B.2)
Adjust nodes to (d,
¯
d) interval:
d
m
= (x
m
+ 1)
¯
d − d
2
+ d. (B.3)
The policy functions can be solved jointly using (3.2) - (3.4).
For the individual d
t−1
= d
m
, the right hand side of (3.1) can be expressed as
E
t
β
R
d
t
Π
t+1
c
−1
t+1
= E
t
β
R
d
t
Π
t+1
X
ε
t+1
p(ε
t+1
|ε
t
)c
t+1
(d
t
(d
t−1
= d
m
, ε
t
), ε
t+1
)
−1
(B.4)
The next step is to compute the right hand side of (B.4), which requires c
t+1
. With d
t
(d
t−1
, ε
t
) solved using
(3.2) - (3.4), we can compute conditional expectation next period T(ε
t+1
, d
t
) by shifting (3.1) one period
forward. Then, we can solve c
t+1
by shifting the system in (3.2) - (3.4) one period forward. Combining (3.1),
(3.1), and (B.4), we have M × 2 equations for M × 2 variables θ
n,t
(ε
t
):
N
X
n=0
θ
n,t
(ε
t
)T
n
(ξ(d
m
)) = log E
t
β
R
d
t
Π
t+1
X
ε
t+1
p(ε
t+1
|ε
t
)c
t+1
(ε
t+1
, ε
t
, d
t−1
= d
m
)
−1
(B.5)
Note, θ
n,t
(ε
t
) and θ
n,t+1
(ε
t+1
) also enter the right hand side via c
t+1
.
C Equilibrium conditions
Our algorithm uses Dynare to solve the system of equations listed below.
C.1 Individual Households and Their Distribution
Chebyshev coefficients: M × 2 equations in (B.5) for M × 2 variables θ
n,t
(ε
t
) for m = 1, ..., M.
Individual decisions: (3.2) - (3.4) for d
t
(d
m
, ε
t
), l
t
(d
m
, ε
t
), c
t
(d
m
, ε
t
) for m = 0, ..., M. These are
(M + 1) × 2 × 3 equations.
Dynamics of the cross sectional distribution: (3.5) for p(d
t
= d
m
, ε
t+1
) for m = 0, ..., M , (M + 1) × 2
equations for (M + 1) × 2 probabilities.
C.2 Aggregate Variables
Aggregate deposit and labor (2 equations):
46

d
t−1
=
X
ε
t
M
X
m=0
d
m
p(d
t−1
= d
m
, ε
t
) (C.1)
L
t
=
X
ε
t
M
X
m=0
l
t
(ε
t
, d
t−1
= d
m
)p(d
t−1
= d
m
, ε
t
). (C.2)
Equations for aggregate variables in different sectors (31 equations):
Stochastic discount factor: (2.13).
Labor market (3 equations): (A.4) - (A.6).
Production (13 equations): capital producers (A.10) and (A.12), wholesale firms (A.21) - (A.23) and
(A.25) - (A.29), retailers (A.15) - (A.17).
Financial intermediaries (10 equations): (2.11), (2.12), (2.16) - (2.20), (A.35) - (A.37).
Fiscal authority, central bank, and monetary policy (4 equation): (2.24) - (2.27).
Aggregation (14 equations):
Exogenous processes (4 equations): (2.28), (A.30) - (A.32).
Bond market clearing conditions (2 equations): (A.33) and (A.34).
Aggregation for retailers and labor market (6 equations): (A.18) - (A.20), (A.7) - (A.9).
Dividend and aggregate resource constraint (2 equations): (A.38) and (A.39).
These are 47 equations for 47 variables
n
K
t
, L
t
, d
t
, R
F
t
, R
re
t
, R
d
t
, Q
t
, Ω
t
, Π
t
, λ
t
, ϕ
t
, re
t
, n
t
, C
t
, w
t
, p
∗
t
, x
1,t
,
x
2,t
, p
m,t
, Y
t
, Y
m,t
, I
t
, p
k
t
, f
m,t
, M
1,t
, M
2,t
, f
cb,t
, A
t
, f
t
, v
p
t
, R
B
t
, Q
B,t
, G
t
, T
cb,t
, b
t
, b
cb,t
,
ˆ
I
t
, T
t
, div
t
, Λ
t−1,t
, mrs
t
,
L
d,t
, w
∗
t
, f
1,t
, f
2,t
, v
w
t
, u
t
o
.
D Solving for the Stationary Equilibrium
(Step 1) Given aggregate deposit and labor supply d, L, we compute steady states for all aggregate vari-
ables.
(Step 2) Solve for the steady state of the Chebyshev coefficients ϑ(ε) = [θ
0
(ε), ..., θ
N
T
(ε)] that approximate
the conditional expectation function. We use the Chebyshev grid d
m
for m = 1, ..., M, where d
m
is
computed using (B.3).
(Step 2.1) Compute the Chebyshev polynomial T
n
(ξ(d
m
)) using (B.1).
(Step 2.2) Initialization
(Step 2.2.1) Initialize by assuming d
t
= d
t−1
= d
m
, and l =
¯
l, then we can solve consumption
c
(0)
(ε, d
m
) using (3.4).
(Step 2.2.2) Compute the right hand side of (B.5) using c
(0)
(ε, d
m
) from the previous step.
(Step 2.2.3) For each ε, we have a system of M linear equations in (B.5). We can use them
to solve M unknowns in ϑ(ε), and call it ϑ
(0)
(ε). The value of the equation computed
in the previous step is T(d
m
, ϑ
(0)
(ε)).
(Step 2.3) This step outlines how we update from ϑ
(j)
(ε) to ϑ
(j+1)
(ε). Repeat this step until
ϑ
(j+1)
(ε) − ϑ
(j)
(ε) is within a specified tolerance, and call it ϑ(ε) = ϑ
(j+1)
(ε).
47

(Step 2.3.1) With ϑ
(j)
t
(ε
t
) = ϑ
(j)
(ε), we have computed the conditional expectation T(d
t−1
=
d
m
, ϑ
(j)
t
(ε
t
)) from the previous iteration.
(Step 2.3.2) Compute current period deposit d
t
(ε
t
, d
t−1
= d
m
), consumption c
t
(ε
t
, d
t−1
=
d
m
), and labor supply l
t
(ε
t
, d
t−1
= d
m
) using (3.2) - (3.4) with T(d
t−1
= d
m
, ϑ
(j)
t
(ε
t
)).
Instead of solving a system of equations with kinks, we implement this step as follows:
Assume the borrowing constraint is not binding, in this case
c
t
= T(d
t−1
= d
m
, ϑ
(j)
t
(ε
t
))
−1
(D.1)
Then we can compute l
t
and d
t
subsequently.
Check d
t
against its bound d
– If d
t
≥ d, then we are done with (Step 2.3.2).
– If d
t
< d, then d
t
= d, and we can solve c
t
and l
t
jointly.
(Step 2.3.3) Compute conditional expectation next period T(d
t
(ε
t
, d
t−1
= d
m
), ϑ
(j)
t+1
(ε
t+1
)) by
shifting (3.1) one period forward, where ϑ
(j)
t+1
(ε
t+1
) = ϑ
(j)
(ε), and d
t
(ε
t
, d
t−1
= d
m
) is
from the previous step.
(Step 2.3.4) Compute next period’s consumption c
t+1
(ε
t+1
, d
t
(ε
t
, d
t−1
= d
m
)) by shifting
(Step 2.3.2) one period forward and using T(d
t
(ε
t
, d
t−1
= d
m
), ϑ
(j)
t+1
(ε
t+1
)) from the
previous step.
(Step 2.3.5) Compute the right hand side of (B.5) using c
t+1
(ε
t+1
, d
t
(ε
t
, d
t−1
= d
m
)) from the
previous step.
(Step 2.3.6) For each ε
t
, we have a system of M linear equations in (B.5). We can use them
to solve M unknowns in ϑ
t
(ε
t
) on the left hand side, and call it ϑ
(j+1)
(ε). The value of
the equation computed in the previous step is T(d
t−1
= d
m
, ϑ
(j+1)
t
(ε
t
)).
(Step 3) Use the histogram approximation of of Young (2010) to approximate the distribution. We approx-
imate over the grid {d
m
}
M
m=0
, which is the same as the Chebyshev grid in (B.3) with one additional
point at the borrowing constraint d
0
= d.
(Step 3.1) Compute conditional expectation and policy functions at the borrowing constraint d
0
= d.
Compute the conditional expectation T(d
t−1
= d
0
, ϑ
t
(ε
t
)) with ϑ
t
(ε
t
) = ϑ(ε) from (Step 2.3).
Then compute policy function d
t
(ε
t
, d
t−1
= d
0
), c
t
(ε
t
, d
t−1
= d
0
), l
t
(ε
t
, d
t−1
= d
0
) following
(Step 2.3.2).
(Step 3.2) Iterate the transition dynamics in (3.5) forward on the {d
m
, ε} grid:
(Step 3.3.1) Start with an initial guess for p(d
0
= d
m
, ε
1
)
(Step 3.3.2) Use the transition probabilities in (3.6) and (2.2) to move one period forward
from p(d
τ−1
= d
m
, ε
τ
) to p(d
τ
= d
m
, ε
τ+1
). Iterate until it converges to the stationary
distribution, and call it p(d
t−1
= d
m
, ε
t
).
(Step 3.3) Compute the aggregate deposit
˜
d and labor
˜
L using (C.1) and (C.2) where p(d
t−1
= d
m
, ε
t
)
is from the previous step, and l
t
(ε
t
, d
t−1
= d
m
) is from (Step 2.3.2).
The above steps compute
˜
d,
˜
L given d, L. This amounts to a fixed point problem. We solve this fixed point
problem by iterating over these steps.
48

E Calibration
Table E.1: Additional Calibration
Parameters Value Target Description
SW parameters
κ 1 − 40
−1
bond duration = 40 Coupon decay parameter
ψ 0.81 Fraction of investment from debt
σ 0.95 Intermediary survival probability
θ 400(R
F
− R
d
) = 3 Recoverability parameter
X Leverage = 4 Transfer to new intermediaries
∆ 1/3 Government bond recoverability
b
cb
b
cb
Q
B
4Y
= 0.06 Steady state central bank Treasury holdings
f
cb
0 Steady state central private bond holdings
ρ
b
0.8 AR central bank Treasury
ρ
f
0.8 AR central bank private bonds
¯
b
G
B
G
Q
B
4Y
= 0.41 Steady state government debt
G
G
Y
= 0.2 Steady state government spending
Standard parameters
β 0.995 Discount factor
η 1 Inverse Frisch elasticity
α 0.33 Production function exponent on capital
δ
0
0.025 Steady state depreciation
δ
1
u = 1 Utilization linear term
δ
2
0.01 Utilization squared term
κ
I
2 Investment adjustment cost
Π 1 Steady state (gross) inflation
ϵ
p
11 Elasticity of substitution goods
ϵ
w
11 Elasticity of substitution labor
ϕ
p
0.75 Price rigidity
ϕ
w
0.75 Wage rigidity
γ
p
0 Price indexation
γ
w
0 Wage indexation
ρ
r
0.8 Taylor rule smoothing
ϕ
π
1.5 Taylor rule inflation
ϕ
y
0.25 Taylor rule output growth
ρ
A
0.95 AR productivity
ρ
G
0.95 AR government spending
Shock sizes
s
A
0.0065 SD productivity
s
G
0.01 SD government spending
s
r
0.0025 SD monetary policy
s
f
0.0025 SD central bank private bonds
s
b
0.0025 SD central bank Treasury
49
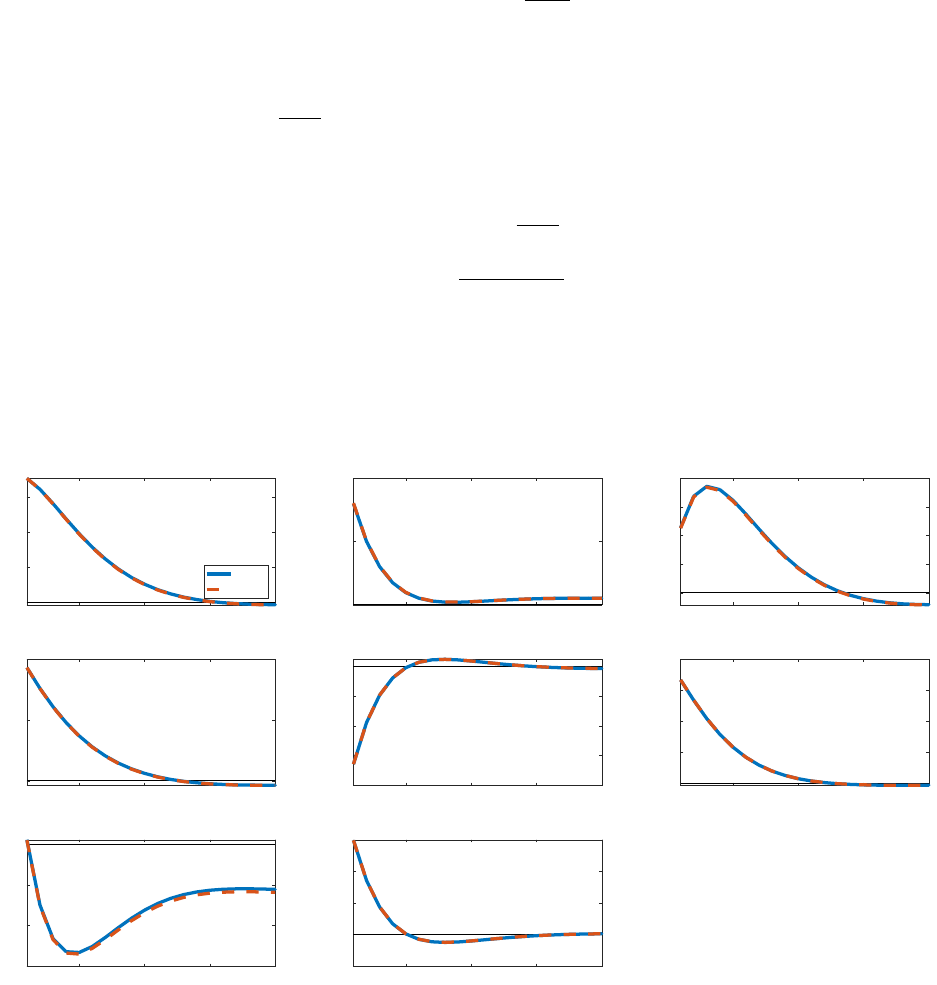
F RANK Household
In the representative agent model, the lifetime utility of the household is
E
0
∞
X
t=0
β
t
log C
t
− χ
L
1+η
t
1 + η
!
,
The flow budget constraint is
d
t
=
R
d
t−1
Π
t
d
t−1
+ mrs
t
(1 − τ)L
t
− C
t
− T
t
+ div
t
− X, (F.1)
The first order conditions are
C
−1
t
= βR
d
t
E
t
C
−1
t+1
Π
t+1
(F.2)
L
η
t
=
(1 − τ)mrs
t
χC
t
. (F.3)
G Conventional Monetary Policy
Figure G.1: Impulse responses under a monetary policy shock
5 10 15 20
0
0.2
0.4
0.6
output
RANK
HANK
5 10 15 20
0
0.5
1
consumption
5 10 15 20
0
0.5
1
1.5
2
investment
5 10 15 20
0
0.5
1
labor
5 10 15 20
-0.2
-0.15
-0.1
-0.05
0
policy rate
5 10 15 20
0
0.05
0.1
0.15
0.2
inflation
5 10 15 20
-0.3
-0.2
-0.1
0
deposit
5 10 15 20
-0.05
0
0.05
0.1
0.15
corp. bond spread
Notes: This figure plots the impulse responses of aggregate variables under a 0.25% monetary policy shock.
The blue solid lines are for the RANK model, and the red dashed lines are for the HANK model. X-axis is
time in quarters, and Y-axis is the percentage change from steady state.
50
